
【重磅】Google 分布式 TensorFlow,像 Android 一样带来 AI 复兴?
Google发布了分布式 TensorFlow。
今天,Google发布了分布式TensorFlow。Google 的博文介绍了 TensorFlow 在图像分类的任务中,100 个 GPUs 和不到 65 小时的训练时间下,达到了 78% 的正确率。在激烈的商业竞争中,更快的训练速度是人工智能企业的核心竞争力。而分布式 TensorFlow意味着它能够真正大规模进入到人工智能产业中,产生实质的影响。

Google 今天发布分布式 TensorFlow 版本!
即便 TensorFlow 在 2015 年底才出现,它已经吸引了全球机器学习开发者的目光。
Google 创始人 Eric Schmidt 坚信 TensorFlow 是 Google 的未来。深度学习引擎+云服务平台,将会带来编程范式的改变:不仅给电脑编程,而且让电脑拥有一定的自主能力。
根据 Github 的数据统计,TensorFlow 成为了 2015 年最受关注的六大开源项目之一。考虑到 TensorFlow 仅仅在 12 月才发布,一个月的时间就让它成为世界关注的焦点。
不过那时候的 TensorFlow,还仅仅是只能在一个机器上运行的单机版本。这意味着它虽然设计精巧,但很难被公司、组织大规模的使用,也很难对产业造成实质的影响。
但今天发布的分布式 TensorFlow,最突出的特征是能够在不同的机器上同时运行。虽然说并不是所有人都需要在几千台服务器上运行 TensorFlow,但研究者和创业公司的确能在多台机器运行的 TensorFlow 中获益。
TensorFlow 技术负责人 Rajat Monga 解释了分布式 TensorFlow 的延期发布:“我们内部使用的软件栈(Software Stack),和外部人们使用的非常不同......所以要让它变得开源,对于我们来说是极其困难的事情。”
经过 5 个月的等待,分布式 TensorFlow 终于到来了。
Google Brain 负责人:Jeff Dean
TensorFlow 0.8 今天发布了,它有一些很好的改进。它为分布式的版本做了一些改变,而且把它们包裹起来使之更容易使用。这篇博客还介绍了用分布式系统训练卷积图像识别模型的一些可扩展的数字。
Google 官方博客介绍
TensorFlow:
TensorFlow 是为使用数据流程图的数值计算开发的开源软件库。图中的节点表示数学运算,而图的边代表着彼此沟通的多维数据阵列(Tensors)。在只使用单个 API 的情况下,灵活的架构可以让你在桌面、服务器或者移动设备的单个或多个 CPUs 和 GPUs 部署计算。TensorFlow 最早由 Google Brain 团队的研究人员和工程师研发,目的是管理机器学习和深度神经网络的研究工作,但是这个系统也足够通用,适用于其他的应用领域。
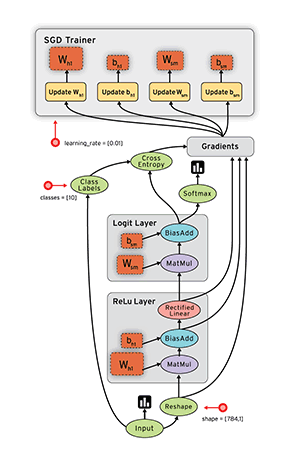
TensorFlow 0.8:支持分布式计算

Google 在很多的产品中都使用了机器学习技术。为了不断改进我们的模型,最为重要的是训练速度要尽可能的快。要做到这一点,其中一个办法是在几百台机器中运行 TensorFlow,这能够把部分模型的训练过程从数周缩短到几个小时,并且能够让我们在面对不断增加的规模和复杂性的模型时,也能够进行实验。自从我们开源了 TensorFlow,分布式的版本就成为最需要的功能之一了。现在,你不需要再等待了。
今天,我们很兴奋的推出了 TensorFlow 0.8,它拥有分布式计算的支持,包括在你的基础设施上训练分布式模型的一切支持。分布式的 TensorFlow 由高性能的 gRPC 库支持,也能够支持在几百台机器上并行训练。它补充了我们最近的公布的 Google 云机器学习,也能够使用 Google 云平台训练和服务你的 TensorFlow 模型。
为了和 TensorFlow 0.8 版本的推出保持一致,我们已经发表了一个“分布式训练”给 TensorFlow 模型库的生成图像分类的神经网络。使用分布式训练,我们训练了生成网络(Inception Network),在 100 个 GPUs 和不到 65 小时的训练时间下,达到了 78% 的正确率。即便是更小的集群,或者只是你桌子下面的几台机器,都可以受益于分布式的 TensorFlow,因为增加了更多的 GPUs 提升了整体的吞吐量,并且更快生成准确的结构。
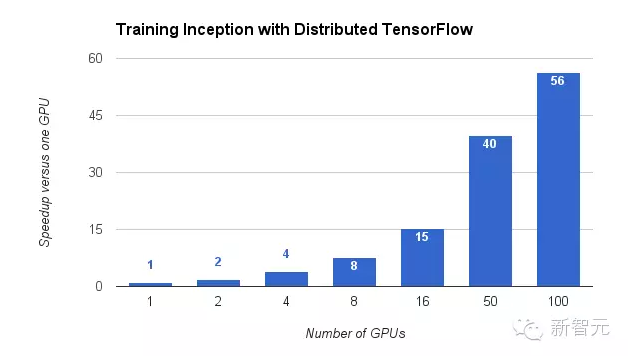
图:TensorFlow 可以加快训练生成网络的速度,使用 100 个 GPUs 能达到 56 倍。
分布式训练也支持你使用像 Kubernetes 这样的集群管理系统,以进行扩大规模的训练。更进一步说,一旦你已经训练了模型,就可以部署到产品并且加快在 Kubernetes 使用 TensorFlow 服务的推理速度。
除了分布式生成器,TensorFlow 0.8 还发布了定义你自己分布式模型的新库。TensorFlow 分布式架构允许很灵活的定义模型,因为集群中的每个进程都可以进行通用的计算。我们之前的系统 DistBelief(像很多追随它的系统)使用特殊的“参数服务器”来管理共享的模型参数,其中的参数服务器有简单的读/写接口,以更新共享的参数。在 TensorFlow 中,所有的计算,包括参数的管理,都会在数据流的图中呈现,并且系统会把数据流映射到不同设备的可用处理器中(例如多核 CPUs,一般用途的 GPUs,手机处理器等)。为了让 TensorFlow 更好使用,我们也推出了 Python 的库,使之更容易写模型,在一个处理器中运行,并且扩展到使用多个副本以进行训练。
这种架构使得它可以更容易的扩大单进程的工作到集群中,同时还可以进行新颖的分布式训练架构的实验。举个例子,我的同事最近展示了“重新访问分布式同步 SGD”(Revisiting Distributed Synchronous SGD),在 TensorFlow 图部署,实现了在图像模型训练中更好的“时间-精度”。
目前支持分布式计算的 TensorFlow 版本还仅仅是个开始。我们将继续研究提高分布式训练表现的方法,既有通过工程的,也有通过算法的改进,我们也会在 GitHub 社区分享这些改进。
抢先尝试
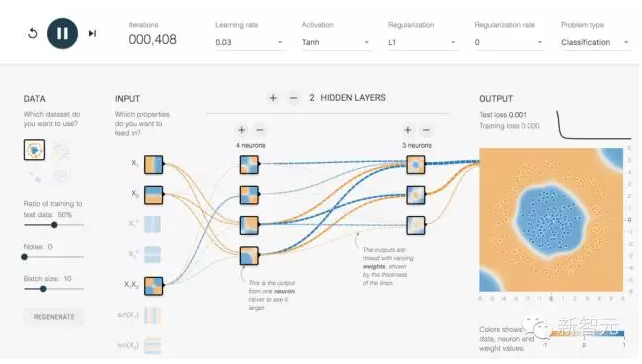
如果你想跳过复杂的按照过程,感受 TensorFlow,Google 提供了一个基于浏览器的模拟器,能让你感受基本的 TensorFlow 和深度学习。
首先在左边选择你要分析的数据,然后在中间选择和组合道具,最后看输出的结果是如何和最早的数据相匹配。最开始看起来会显得很可笑,但是这很好理解,而且能在抽象层面理解神经网络是如何运作的。
领导成员
TensorFlow 训练库(TensorFlow training libraries)
:Jianmin Chen, Matthieu Devin, Sherry Moore and Sergio Guadarrama
TensorFlow 内核(TensorFlow core)
:Zhifeng Chen, Manjunath Kudlur and Vijay Vasudevan
测试(Testing)
:Shanqing Cai
生成模型架构(Inception model architecture)
:Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Jonathon Shlens and Zbigniew Wojna
项目管理(Project management)
:Amy McDonald Sandjideh
工程领导(Engineering leadership)
:Jeff Dean and Rajat Monga
TensorFlow 更新历史
2016.4.13
Announcing TensorFlow 0.8 – now with distributed computing support!
2016.3.23
Machine Learning in the Cloud, with TensorFlow
2016.3.23
Scaling neural network image classification using Kubernetes with TensorFlow Serving
2016.3.9
Train your own image classifier with Inception in TensorFlow
2016.2.16
Running your models in production with TensorFlow Serving
2016.1.21
Teach Yourself Deep Learning with TensorFlow and Udacity
2015.12.7
How to Classify Images with TensorFlow
2015.11.9
Google’s latest machine learning system, open sourced for everyone
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 Google
TensorFlow
人工智能
Google
TensorFlow
人工智能