
Facebook推出人工智能引擎DeepText,让机器更好的理解语言和内容
Facebook 人工智能研究团队与应用机器学习团队合作,推出了一款文本理解引擎 DeepText ,试图让它理解用户贴出的每篇文章。
【编者注】本文作者:Ahmad Abdulkader、Aparna Lakshmiratan、Joy Zhang,由机器之心编译,参与:孙睿、微胖

引言:前几天,有新闻报道在查举不良图片方面,Facebook的人工智能战胜了人工。今天,这家公司人工智能研究团队与应用机器学习团队合作,推出了一款文本理解引擎 DeepText ,试图让它理解用户贴出的每篇文章。媒体预测,这款人工智能引擎将会深刻变革公司核心产品体验。 Clarifai CEO Matthew Zeiler 曾说,谷歌真不是一家搜索公司,而是机器学习公司。谷歌 CEO 也多次表示,公司正在践行「AI 优先」的理念。Facebook 或许与之殊途同归?
Facebook 的搜索世界比不上谷歌的大,不过,其规模仍然蔚为可观。
有超过十亿用户每天都会刷Facebook,网络服务器上每天有数万亿的状态更新,活动邀请,相册以及视频。Facebook 正坐拥日益增长的海量数据。公司一直希望通过真正理解这些信息,将那些拥有共同兴趣的人有效连接起来,帮助用户找到正在寻找的东西,卖出更多的广告。
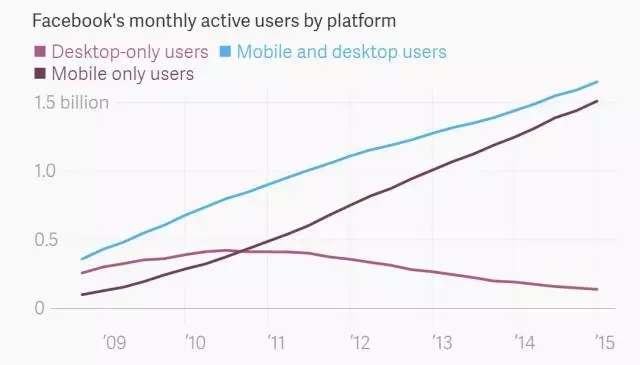
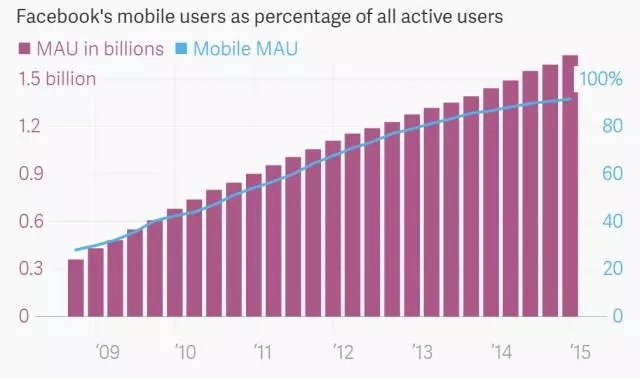
Facebook 已经使用了用户共享的人口数据信息。不过,Facebook 希望打造新的功能,追踪网站上的所有信息,就像谷歌抓取整个互联网信息并作出索引。对于Facebook 用户来说,这意味着,他们可以更加容易地找到埋藏在那些数以万亿计博文中的有用信息,这就像去年谷歌开始使用人工智能,试图真正理解用户查询,将真正相关的信息呈现在搜索结果中。
正如公司博文所介绍的:
文本,是Facebook 上流行的沟通方式。理解Facebook 上各种不同文本使用方式,有助于改善用户体验,无论是让更多用户喜闻乐见的内容呈现出来,还是过滤掉讨厌的内容,比如垃圾邮件。
去年,Facebook 已经升级了自己的搜索功能,将更多的搜索结果包括进来。比如,搜索“taco(墨西哥卷饼),你会得到包括朋友发的taco照片或者与taco有关的新闻报道。
不过,理论上,Deep Text 可以让搜索更进一步。
DeepText是一款基于深度学习的文本理解引擎,每秒能理解几千篇博文内容,语言种类多达20多种,准确度近似人类水平。
比如,当一些好友或者品牌上po 出与taco有关的内容是,它可以分析出他们到底在说什么,然后给出最有用的结果。比如,如果你想要知道哪里可以买到好的taco,它可能会分析你朋友当中关于taco相关的博文中的内容,给你推荐一家可以吃到taco的餐馆。如果你在查询taco对健康有哪些好处,他会推荐这方面的最新科学文章。
DeepText 充分利用了几个深度神经网络结构,包括卷积和循环(recurrent)神经网络,并能完成以单词、字符为基础的学习任务。我们使用 Fb Learner Flow 和 Torch 进行模型训练。通过 FBLearner Predictor 平台(提供可扩展且可靠的分布式架构),轻松点击按键就能调用训练过的模型。Facebook 的工程师们能够通过DeepText 提供的自助服务结构,轻松打造新的 DeepText 模型。
为什么采用深度学习?
文本理解包括多项任务,比如,通过一般分类来决定某篇博文内容是否与篮球有关——以及识别实体,比如演员名字以及其他有意义的信息。不过,想要接近人类的理解水平,我们需要让计算机学会理解一些事情,比如俚语和语义消歧。比如,如果某人说,「我喜欢 blackberry 」,这是指水果还是电子设备?
理解 Facebook 上的文本需要解决两个难题:棘手的体量上的挑战以及语言难题,传统自然语言理解技术在这两个问题上没效果。使用深度学习,我们可以更好地了解多种语言文本,在使用标签数据方面,也比传统自然语言理解技术高效地多。DeepText 以深度学习为基础,并延伸了其中思想,深度学习最初源自 Ronan Collobert 以及 Yann LeCun 的 Facebook AI Research。
1.更加快速地理解更多语言
Facebook 社区确实全球化,因此,对 DeepText 来说,尽可能多地理解不同语言很重要。传统自然语言理解需要丰富的、建立在复杂工程学以及语言知识上的预处理逻辑。当人们使用俚语或不同拼写方式交流同一想法时,即使在同一种语言中,也会存在变化。使用了深度学习,我们就可以减少对语言依赖性知识的依靠,因为系统可以从文本中学习,几乎不需要预处理。这有助于我们以最小的工程学成本迅速解决多语言问题。
2. 更加深入地理解
在传统自然语言处理方法中,语词被转为一种机器算法可以理解的形式。比如,「brother」可能用一个完整ID表示,比如4598,而「bro」可能会使用另一种表示,比如 986665。这种表征方式要求训练数据中,每一个会被看到、有具体拼写的单词都要得到理解。
如果使用深度学习,我们就可以使用「词嵌入(word embeddings)」,一个保存单词之间语义联系的数学概念。因此,合理计算后,我们就可以看到「brother」和「bro」的词嵌入距离很近。这类表征方式可以让捕捉到更为深入的单词语义意思。
使用字嵌入,我们还可以理解不同语言中的相同语义表达。比如,英语的「Happy birthday」和西班牙语的 「feliz cumpleaños」,在共同的嵌入空间中,彼此应该非常接近。通过将语词和短语映射到一个共同的嵌入空间,DeepText 就能建造起与语言无关( language-agnostic)的模型。
3.标签数据的匮乏
书面语言,尽管具有上面提到的诸多变化,但是,通过使用无监督学习,我们也可以从未标签文本中提取出许多结构。深度学习为充分利用这些嵌入提供了好的框架,通过使用小规模的标签数据组,就能进一步精细化它们。这是胜过传统方法的显著优势,后者通常需要大量人类标签过的数据,这不仅低效,也很难适应新任务。在许多情况下,无监督学习和监督学习的结合,可以显著提升效果,因为弥补了标签数据组的不足。
Facebook 上的探索
我们已经在一些 Facebook 的使用体验中,测试 DeepText 了。例如,Messenger 现在能够更好地了解某个人可能想去某个地方。DeepText 被用于感知用户意图和提取要点,当用户说「我刚从出租车里出来」时,它能够理解这句话与「我需要一辆车」的区别,从而不会误解成用户在找出租车。
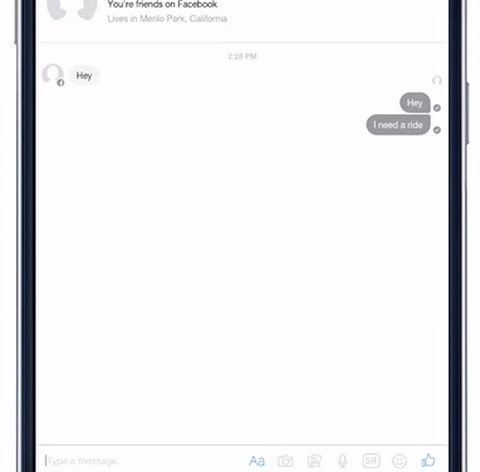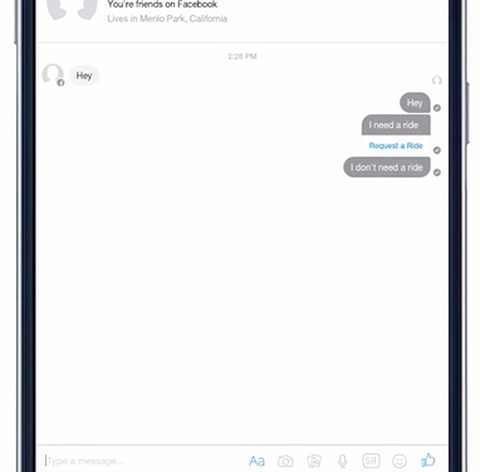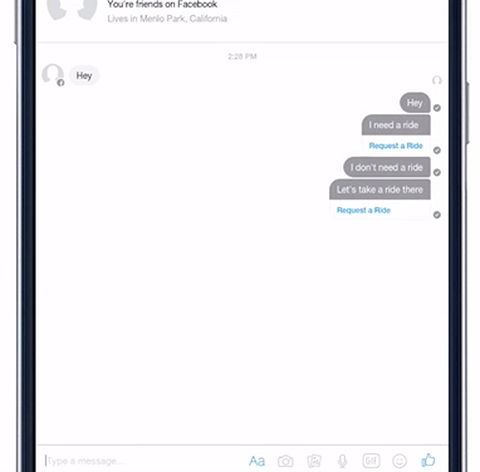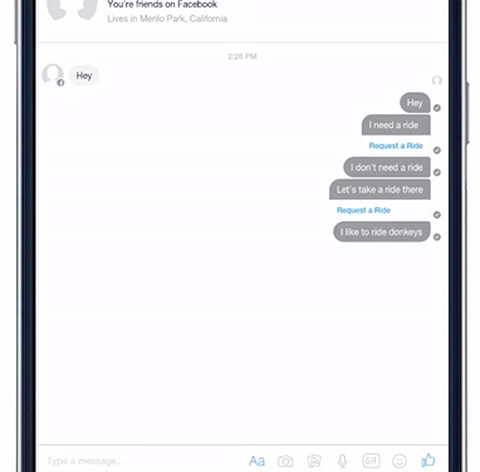
DeepText 帮助 Messenger 识别用户用车需求,并建议用户使用Uber或Lyft
不过,鉴于 Tay 事件效应,Facebook 机器学习团队的工程主管 Mehanna 并没有确认公司是否已经将Deep Text 用于 M,一款以人工智能为基础的虚拟助手。不过,他确实说,Deep Text 「正在 Messenger 上缓慢而更加广泛地铺开。」
我们也开始使用高精确度、多语言的 DeepText 模型,来帮助人们寻找他们需要的工具。例如,用户可能会发一条状态说「我的自行车 200 美元出售,有感兴趣的吗?」通过提炼售卖物品和价格等信息,DeepText 能够发现这条状态是关于售卖某样东西的,并向用户推荐在 Facebook 平台上的相关产品.
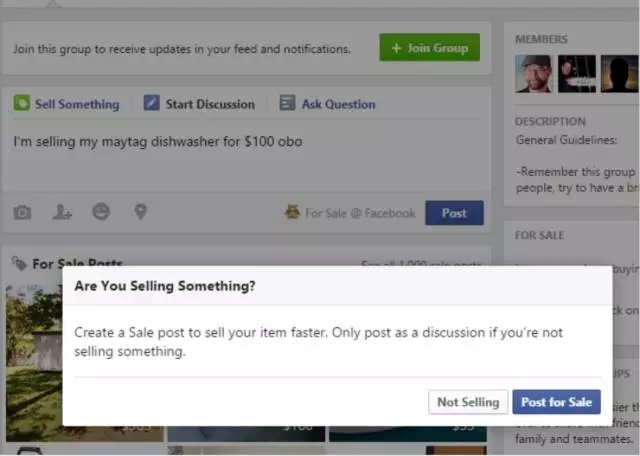
通过理解博文内容,提取其中意图、情感和实体(比如,人物、地点和事件),DeepText 有望进一步提升FB 体验,使用混合的内容信号,比如文本和图片并自动去除会被拒绝的内容,比如垃圾邮件。许多名人和公众人物都在使用 Facebook 与大家交流,这些互动往往会产生几百甚至上千条评论。要从这些不同语言的评论中找出最有关联的内容,同时保证评论质量,到现在还是一个挑战。所以, DeepText 还有可能解决的另一个难题就是,找出关联性最高或最有质量的评论。
下一步
我们不会停止改进 DeepText 的脚步,我们也在与 Facebook 的人工智能研究小组合作,探索它的应用。以下是一些例子。
1.更好地了解人们的兴趣所在
个性化 Facebook 用户体验的任务之一,就是向用户推荐他们感兴趣的内容。为了做到这一点,我们必须首先能够将任何文本与某一特定话题相关联,而这需要大量的标签数据。
虽然这类数据集很难手动生产,但是,我们正在尝试通过公开的 Facebook 页面,来生成含有半监督标签的大型数据集。 我们有理由假定,这些页面上的信息将代表一个专门话题——例如,Steelers 页面的状态会包括 Steelers 橄榄球队的信息。我们用这类内容训练一个我们称为 PageSpace 的大众兴趣分类器(a general interest classifier),而它的技术核心就是 DeepText。反过来,这也将进一步改善其他 Facebook 体验中的文本理解系统。也就是说,团队会使用匹兹堡 Steelers 的页面来学习人们如何谈论美式足球以及 Steelers。所有这种数据会帮助团队建立起一个了解人类在线聊天方式、以及语词与句子联系的人工智能系统。
2.文本的和视觉内容的综合理解
人们经常会发一些含有图片或视频的状态,并用文字来描述相关内容。在这类情况下,了解用户意图离不开对文本和图像内容的共同理解。
例如,你的朋友发了一张自己的小宝宝的照片,然后在正文里写「第 25 天」。无论是单看图片,还是仅阅读文本,都没办法搞清楚这篇博文到底什么意思。但是,如果一起分析图片和文本,系统就可以根据经验猜出内容,这些经验告诉系统,孩子是用户贴出图片的一部分,而且这位用户每天都会贴出这样的图片,这张图片不过是其中一分部。这样,系统就能正确将这张博文划分到标题为「家庭新闻」的类别中,并将它展示给过去那些对用户”家庭新闻“感兴趣的好友们。
将图像和文本结合之后,我们能很清楚地知道,这条状态分享了家庭新添成员的信息。我们正在与 Facebook 的图像内容分析团队合作,来构建能够将文本和图像信息相结合的深度学习架构。
3.新深度神经网络架构
我们在持续地开发和寻找新的深度神经网络架构。双向循环神经网络(BRNNs)看起来可能会很有希望,因为它们有两个目标,通过循环(recurrence)获得单词间的语境依存(contextual dependencies),以及通过卷积捕捉位置不变的(position-invariant)语义。比起用以分类的常规卷积或循环神经网络,我们发现 BRNNs 在分类时的错误率更低;有时错误率甚至只有 20%。
将深度学习技术应用于文本理解,会继续提升 Facebook 的产品和用户体验质量,而反过来也是如此。对文本理解系统来说,Facebook 产生的非结构化数据,是它们从语言中自动学习的绝好机会,因为使用不同语言的人都会自然用到它,而这也会进一步推动最先进的自然语言处理技术。
Hussein Mehana 说,「朝着打造能智能地与人类交流的机器,我们又迈出了一步。」不过,对于 Facebook 最受欢迎的产品,从Messenger 到 新闻推送来说,Deep Text 带来的变革到底有多深,还有待观察。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 Facebook
人工智能
Facebook
人工智能