
机器人也会造假、有偏见?原因在这
报假新闻、推不雅视频?机器学习算法这是怎么了?
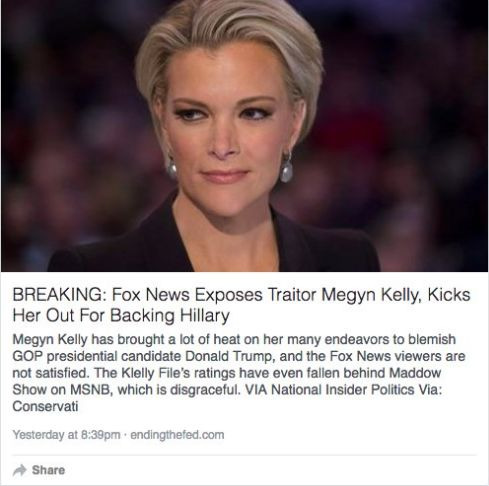
前段时间,Facebook将人类编辑解雇,并让人工智能担任热门榜单的编辑。然而,在上任之后,该机器学习算法连续几天将几条不实新闻以及不雅视频推上热门榜单,其中包括宣称福克斯新闻炒掉了知名主持人Megyn Kelly并称其为“叛徒”,没过多久此则新闻就得到了当事人及相关人员辟谣。
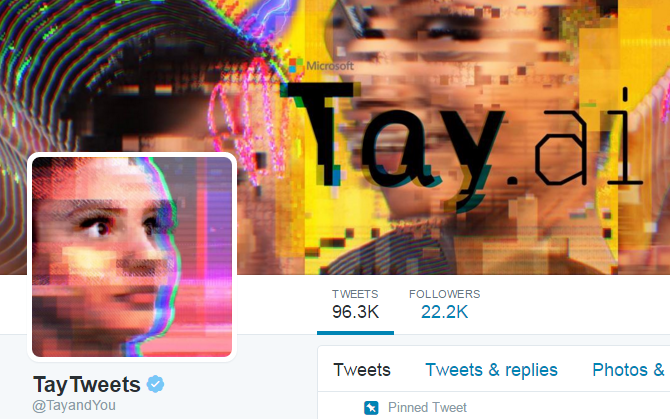
此外,在今年3月23日,微软悄悄的推出了一款聊天机器人Tay。Tay最初是以一个清新可爱的少女形象出现,但是由于她的算法设定是通过学习网友的对话来丰富自己的语料库,很快她被网友充斥着激烈偏见的话语“带坏”,变成了一个彻底的仇视少数族裔、仇视女性、没有任何同情心的种族主义者。
种种现象看来,机器学习也不是那么的完美,这到底是如何造成的?而且,在智能汽车领域,研究人员意图将机器学习运用到人工智能车载系统上,并让其学会车主的驾驶习惯。但是,在看了上面的例子之后,为了打造更好的机器学习算法,我们应该做些什么?

为何机器学习总是出错?
简单来说,机器学习的原理就是用大量的数据对算法进行训练,从而达到理解人、学习人的目的。从中我们可以知道,这其中最重要的就属算法的“学习”过程。
以Tay的偏见为例,关于这个,在一个月前,谷歌的一个数据库貌似给出了答案。
两年前,谷歌的几个研究员启动了一个神经网络项目,目标是找出单词相邻组合的各种模式,而所要使用的语料库来自谷歌新闻文本中的300万个单词。虽然结果很复杂,但团队人员发现可以用向量空间图来展示这些模式,其中大约有300个维度。

在向量空间中,具有相似意义的单词会占据同一块位置,而单词间的关系,可以通过简单的向量代数来捕捉。例如,“男人与国王就相当于女人与王后”,可以使用符号表示为“男人:国王::女人:王后”。相似的例子有,“姐妹:女人::兄弟:男人”等等。这种单词之间的关系被称为“单词嵌入”。
最后,蕴含了诸多单词嵌入的数据库被称为Word2vec。之后的几年内,大量研究人员开始使用它帮助自己的工作,比如机器翻译和智能网页搜索。

但是有一天,波士顿大学的Tolga Bolukbasi的和几位来自微软研究院的人员发现,这个数据库存在一个很大的问题:性别歧视。
比如说,你在数据库里询问“巴黎:法国::东京:x”时,系统给你的答案是x=日本。但是,如果问题变为“父亲:医生::母亲:x”时,给出的答案是x=护士;再比如问题“男人:程序员::女人:x”,答案为 x=主妇。
这种答案在一定程度上已经算是一种性别歧视了。而据分析,个中原因是Word2vec语料库里的文本本身带有性别偏见,之后的向量空间图随之也受到影响。
由此我们可以看出,机器学习之所以会出错,某种程度上还是归于“学习资料”的“不太正经”,以及算法那种什么都学的性质。

这种错误是否可以避免?
讲真,以当前的技术来讲,这种现象是很难杜绝的。如果要杜绝这种情况的出现,那不仅涉及到技术层面,还有社会道德层面。

先看社会道德层面。机器学习算法的数据来源于人们的语言、行为习惯等,以软银计划打造的人工智能汽车为例。7月份,软银与本田达成合作,联手打造一辆能够阅读驾驶员情绪并与之交流的汽车,在行驶过程中,系统中的机器学习算法可以学习驾驶员的驾驶习惯,从而在无人驾驶模式开启时,能够给予驾驶者最舒服、毫无违和感的的驾驶体验。但是,如果该驾驶员有不良驾驶习惯,那将会对算法的学习提供错误的示范。
这仅仅是驾驶习惯,而在语言方面,其中可能包括暴力、侮辱等等字眼,相比于驾驶习惯,这些更难以约束。因而,在学习对象都不能“正经”的情况下,又怎么将机器学习算法调教完美?

再看技术层面,这也得从数据方面下手。如果想要好好的训练算法,研究人员就得剔除数据中的不良信息和隐藏的逻辑,再让算法分别识别。但从这里我们就可以了解到,这是对于研究人员而言,将是一项极其繁重、极具难度的工作。而且,抠字眼还是比较简单的了,最难搞的还是字里行间的逻辑关系,一不小心就是一个大坑。不管是人类,还是机器,对于这种识别都是一个难以跨越的坎儿。
以此种种来看,机器学习固有它的好处,但我们还是不能过于依赖,尤其是涉及到一些复杂的工作,比如开车、聊天等情形。不过,虽然当前这个问题很难解决,但随着人工智能技术的发展,说不定哪天研究人员就能想到一个法子,从而彻底解决这个问题。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 人工智能
机器学习
人工智能
机器学习