
【重磅】谷歌开源大规模语言建模库,10亿+数据,探索 RNN 极限
谷歌今天宣布开源大规模语言建模模型库,这项名为“探索RNN极限”的研究今年 2 月发表时就引发激论,如今姗姗来迟的开源更加引人瞩目。
【编者按】本文转载自新智元,来源:arXiv.org,译者:胡祥杰
开源说明
根据谷歌大脑团队在Github发布的消息,他们这次发布开源了一个在英语语料库 One Billion Word Benchmark(http://arxiv.org/abs/1312.3005)预先训练过的模型。这个数据库含有大约10亿个单词,词汇有80万单词,大部分都是新闻数据。由于训练中句子是被打乱了的,模型可以不理会文本,集中句子层面的语言建模。
在此基础上,作者在论文描述了一个模型,混合了字符CNN(character CNN)、大规模深度LSTM,以及一个专门的Softmanx架构,最终得到的结果可以说是迄今最好的。
代码发布
开源部分包括:
1.TensorFlow GraphDef proto buffer文本文件
2.TensorFlow 预训练 checkpoint shards
3.评估预训练模型的代码
4.词汇表
5.LM-1B评估测试
代码支持4种评估模式:
1.提供数据库,计算模型的perplexity
2.提供前缀,预测后面一个单词
3.softmax嵌入项,字符级别的CNN单词嵌入项
4.输入句子,将转存LSTM状态的嵌入项
结果
更多信息请访问:https://github.com/tensorflow/models/tree/master/lm_1b
研究论文:探索语言建模的极限
作者:Rafal Jozefowicz,Oriol Vinyals,Mike Schuster,Noam Shazeer,Yonghui Wu
摘要
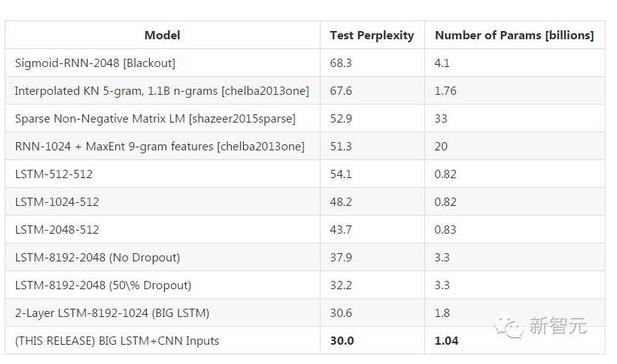
本文中,作者探讨了近年来递归神经网络(RNN)在语言理解的核心——大规模语言建模(LM)方面的发展。为了解决语言建模中的两大挑战:语料库和词汇量,以及复杂的、长期的语言结构,作者拓展了现有模型,在One Billion Word Benchmark上对CNN或LSTM做了彻底研究。单一模型最好成绩将结果从 51.3 提高到30.0(同时将参数数量减少了20倍),模型融合的结果创下了历史记录,将混淆度(perplexity)从41.0下降到23.7。我们将这些模型开源,供所有NLP和ML研究者研究和提高。
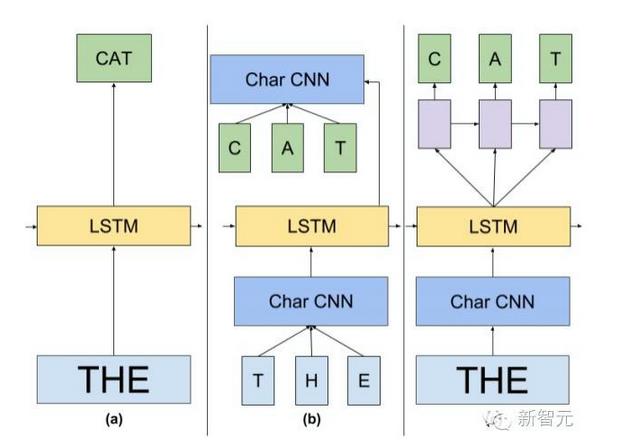
论文呈现的模型中一个高层的图表。a指的是一个标志的LSTM 语言建模;b代表一个LM,其中输入和Softmax嵌入被一个字符CNN取代。c中,我们用一下一个单词预测LSTM网络替代Softmax。
语言建模(LM)是自然语言处理和自然理解模型任务的一个核心任务,能对句子结构分步进行展示,它展示的不仅是语言的复杂内容,比如语法结构,还能提取语料库可能包含的一定数量信息。确实,模型能够把较低的概率指派到那些语法上正确的句子上,但是却不太可能帮助完成其他基础的语言理解任务,比如,回答问题、机器翻译或者文本摘要。
LM在传统的NLP任务中扮演着关键的角色,例如,语音识别、机器翻译、文本摘要。通常(但不是一直),训练语言模型会提升下游任务的潜在价值,比如语音识别中的词语错误率,或者翻译中的BLEU分数),这会让训练更好的LM自身具有更高价值。
进一步说,在大量的数据上进行训练,语言模型会从训练数据中简练地提取解码后的知识。比如,当用电影字幕进行训练时,这些语言模型能够生成关于物体颜色、人物身份等信息的大难。最近提出的序列到序列模型,使用了有条件的语言模型,作为解决多任务难题的一个关键,包括机器翻译和视频生成等 。
深度学习和递归神经网络(RNN)在过去的几年中极大地推动了语言建模研究的发展,让研究者可以在更多的任务上进行探索,在这些任务中,强限制性的独立假设都是不实际的。
虽然事实上,简单的模型,比如N-grams,只使用极少的前词(privious words)来预测接下里会出现的词,它们对于高质量、低混淆的语言建模来说一谈是一个非常关键的组成部分。
确实,最近绝大部分对大型语言建模的研究已经证明了RNN配合N-grams使用效果非常好,因为它们可能有一些不同的优势,能对N-gram模型进行补充。但是,如果单独使用RNN的话,效果就会很差。
我们相信,虽然很多工作都在小型的数据集,比如Penn Tree Bank(PTB)上展开,但是,更大型的任也是很重要的,因为过拟合并不是目前语言建模中的一个主要限制,而只是PTB任务中的一个主要特点。
大型语料库上的结果通常会更好,这很重要,因为许多在小型数据库上运行得很好的想法在大型数据库上做进一步提升时都失败了。进一步来看,考虑到当下的硬件趋势和网页大量可用的文本数据,进行大型的建模将会比过去更加简单。所以,我们希望我们的工作能给研究者带来启发和帮助,让他们在PTB之外可以使用传统的语言模型。
出于这一目的,我们把自己的模型和训练内容进行开源。
我们聚焦在一个著名的大型LM基准:One Billion Word Benchmark数据集。这一数据集比PTB要大很多,同时挑战也多很多。与计算机视觉领域的Imagenet类似,我们认为,在大型数据集上研究,并且在清晰的基准上进行建模将能提上语言建模。
我们工作的贡献主要有以下几个:
1.我们探索、扩展并尝试在大规模LM上整合当下的一些研究;
2.具体地,我们设计了一个Softmax loss,基于特性水平的CNN,在训练上效率很高,在准确度上与完整的Softmax一致,而完整版的要求更多维的参数;
3.我们的研究提升了当下最著名的大规模LM任务:单一模型的 从51.3降到了30.0,同时,参数的系数减少了20;
4.我们证明了,几个不同模型的组合能把这一任务的perplexity降到23.7,这是一个显著的提升。
在论文的第二部分,我们将会对语言建模中的重要概念和前人研究进行综述。第三部分,我们会提出对神经语言建模这一领域的贡献,重点在大规模递归神经网络的训练。第4和第5部分的目的是尽可能地描述我们的经验和对项目的理解,同时把我们的工作与其他相关的研究方法进行对比。
评价及讨论
Reddit、HN和Twitter上的反响都挺好,不过也有人指出了这项研究的一些缺点。根据shortscience.org上的留言;
正如我在上文提到的那样,perplexity 从某处程度上来是一个让人困惑的指标,大的混淆(perplexity)并不反映真正的提升,而是带来楼主“夸大”效应。
这篇论文只提供了语言建模的提升,但是,LM一般都会被嵌入到复杂的使用场景中,比如语音识别或者机器翻译。如果本论文中提供的LM可以分享一下与一些端到端的产品融合的结果,那会更有见解性。鉴于论文的作者在谷歌大脑团队工作,这一要求并不过分。
据我所知,本论文使用的数据库来自新闻报道,这种类型的数据比起口语数据更加规范。在实际的应用中,我们面对的通常是非正式化的数据(比如搜索引擎和语音识别)。论文中提到的最好的模型,能否适应更加实际的应用,目前依然是一个问题。再次的,对于谷歌大脑团队来说,把这一模型融合到既有的系统中进行测试,并不是什么难事。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 语音识别
谷歌
语音识别
谷歌