
关于AI的7个误解 | 人工智能核心概念对比
打破媒体打造的AI神话,告诉你AI的真相到底是什么?
【编者按】:本文转载自新智元,作者:Robin Bordoli,来源:crowdflower
如果你是一名企业主管(而不是数据科学家或机器学习专家),你可能已经从主流媒体的报道中接触过人工智能。你可能在《经济学人》和《名利场》读过相关文章,或读过有关Tesla 自动驾驶的故事,或史蒂芬•霍金写AI对人类的威胁的文章,甚至还看过有关人工智能和人类智能的讽刺漫画。
所以,如果你是关心你的企业发展的高管,这些有关AI的媒体报道可能会引出两个恼人的问题:
第一, AI的商业潜力是真是假?
第二, AI如何应用于我的产品?
第一个问题的答案是肯定的,AI具有商业潜力。今天,企业已经能应用AI改变需要人类智能的自动作业流程。AI能让人力密集型企业处理的工作量增加100倍,同时把单位经济效益降低90%。
回答第二个问题需要多一点时间。首先,我们必须消除主流媒体宣传的AI神话。只有消除这些误解,你才能对怎样应用AI到你的业务中有一个框架。
神话1:AI是魔术
许多主流媒体把AI的描述得想魔术一般神奇,好像我们只需要对谷歌、Facebook、苹果、亚马逊和微软这些大公司的高级魔术师使劲鼓掌。这种描述是帮倒忙。如果我们希望企业采用AI,那么我们就需要让企业家们理解AI。AI并不是魔术。AI是数据、数学、模型以及迭代。要想让AI为企业接受,我们需要更加透明,以下是3个有关AI的关键概念的解释:
训练数据(TD):训练数据是机器学习的初始数据集。训练数据包括输入和预回答输出,所以机器学习模型能够为任何给定输出寻找模式。例如,输入可以是带有客户和企业支持代表(CSR)间的电子邮件线程的客户支持ticket,输出可以是基于企业特定分类定义的从1到5的分类标签。
机器学习(ML):机器学习是能从训练数据中学习模式,并让这些模式应用于新的输入数据的软件。例如,接收到带有客户和CSR间的电子邮件线程的一个新的客户支持ticket时,机器学习模型能预测它的分类,并告诉你它对这个预测的置信度。机器学习的主要特点是它学习新的、而非适用固有的规则。因此,它能通过消化新的数据调整自己的规则。
Human-in-the-Loop(HITL):Human-in-the-Loop是AI的第三个核心要素。我们不能指望机器学习模型绝对可靠。一个好的机器学习模型可能只有70%的准确率。因此,当模型的置信度较低时,就需要人使用Human-in-the-Loop作业流程。
所以,不要被AI是魔术的神话所迷惑。理解AI的基础公式是:AI=TD+ML+HITL。

神话2:AI只为技术精英专属
媒体报道很容易让人产生一种错觉,就是AI只属于技术精英——大公司例如Amazon,Apple,Facebook,Google,IBM,Microsoft,Salesforce,Tesla,Uber——只有它们能够组建大型机器学习专家团队,并获得亿美元级的投资。这种观念是错的。
今天,不用10万美元就能着手应用AI到你的业务中。所以,如果你是美国收益大于5000万美元的26000家企业之一,你就可以把收益的0.2%投资于AI应用了。
所以,AI不是技术精英专属。它属于每个企业。

神话3:AI只为解决十亿美元级别的问题
主流媒体的倾向于报道未来主义的事物,例如自动驾驶汽车或用于运送快递的无人飞机。像Google,Tesla,Uber这些公司由于“赢者通吃”的心态,为了抢占未来无人车市场的龙头老大地位,已经投资进去数百亿美元。这些给人的印象是AI只用于解决十亿美元级别的新问题。但这又是一个错误。
AI也应用于解决现存的较小的问题,例如百万美元级别的问题。让我解释一下:任何一个企业的核心需求都是理解客户。从古希腊的agora市集和古罗马的个人买卖广场就是如此。今天也是如此,哪怕生意买卖爆发性地转移到了互联网上。许多企业坐拥来自客户的非结构化数据宝藏,这些数据来自电子邮件线程或Twitter评论。AI能应用于这些分类支持ticket的挑战,或用于理解推文情绪。
所以,AI不仅能应用于十亿美元级别的令人兴奋的新问题,例如自动驾驶汽车。AI也用于现存的“无趣”的小问题,例如通过支持ticket分类或社交媒体情绪分析更好地理解客户。

神话4:算法比数据更重要
主流媒体中有关AI的报道倾向于认为机器学习算法是最重要的要素。它们似乎把算法等同于人类大脑。它们暗示正是算法让魔术发生作用,更精细复杂的算法能超越人类大脑。有关机器在国际围棋和象棋中战胜人类的报道就是例子。媒体关注的是“深度神经网络”、“深度学习”以及机器如何做决定。
这样的报道可能带给企业这样的印象:想要应用AI,他们得先聘请到机器学习专家来建一个完美的算法。但假如企业不考虑怎样获得更高质量、更大量的定制训练数据以让机器学习模型学习,就算有了完美的算法也可能得不到理想的效果(“我们有超棒的算法”和“我们的模型只有60%的准确率”间的落差)。
从Microsoft,Amazon和Google这些公司购买商用机器学习服务,却没有一个训练数据规划或预算,就好比买了一辆汽车,却没法到达加油站。你只是买了一大块很贵的金属而已。汽车和汽油的类比虽然不够恰当,因为如果你给机器学习模型补给越多的训练数据,模型就能变得越好。这就像汽车每用完一箱汽油,积累的里程数越大。所以训练数据甚至比汽油更重要。
所以,训练数据的质量和数量至少是与算法同等重要的。

神话5:机器>人
过去30年来,媒体一直喜欢把AI描述为比人类强大的机器,例如《终结者》的施瓦辛格和《Ex Machina》的Alicia Vikander。媒体这样做也可以理解,因为媒体想建立起机器和人类之间谁会赢的简单叙述结构。但是,这和实际情况不符。
例如,最近Google的DeepMind/AlphaGo战胜李世石的新闻被媒体简单描述成机器战胜了人类。这是不准确的,真实情况不是这样简单。更准确的描述应该是“机器联合许多人战胜了一个人”。

消除这种误解的核心理由是机器和人类具有互补的能力。请看上图。机器的特长是处理结构化计算,他们会在“找出特征矢量”任务上表现良好。而人类的特长是理解意义和上下文,他们在“找出豹纹连衣裙”任务上表现良好,让人类做“找出特征矢量”的任务就不那么容易了。
因此,对企业来说正确的框架是实现机器和人的互补,AI是机器和人的共同工作。
神话6:AI就是机器取代人类
主流媒体喜欢描绘反乌托邦的未来,因为它们认为这能吸引眼球。这样或许确实能吸引读者眼球,但是,它对真正理解机器和人类如何共同工作没有一点帮助。

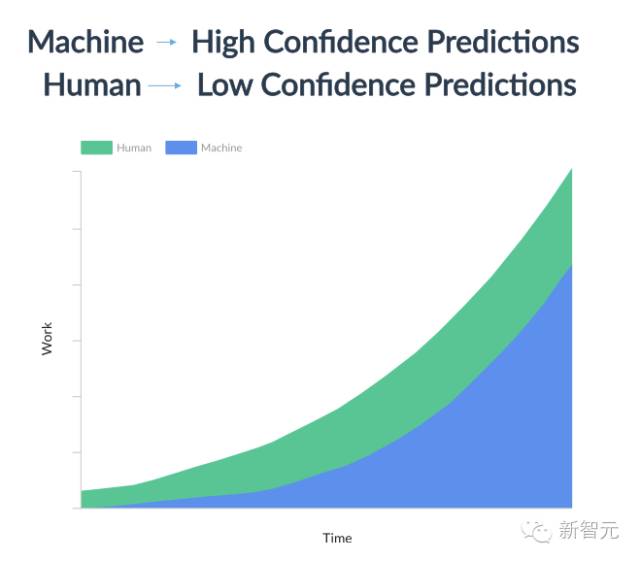
例如,让我们再回到企业分类支持ticket的业务上来。在现今的大多数企业,这还是100%人工的过程。所以,这个过程又慢成本又高,能做的数量受到限制。假设你在分类了10000个支持ticket之后得到了一个准确率为70%的模型。30%的时候结果错误,但这时Human-in-the-loop就可以介入了。你可以把可接受置信度设置为95%,只接受置信度是95%或高于95%的输出结果。那么机器学习模型最初就只能做一小部分工作,比如说5%-10%。但是当模型得到新的人工标记数据时,它就能学习、进步。因此,随着时间的推移,模型能处理更多的客户支持ticket分类工作,企业也能大大增加分类的ticket量。

所以,机器和人联合可以增加工作量,同时保持质量,降低重要业务的单位经济效益。这就消灭了机器取代人类的AI神话。真相是,AI是机器强化人类。
神话7:AI=ML
主流媒体有关AI的最后一个神话是把人工智能和机器学习当做一回事了。这可能让企业管理层以为只要买下Microsoft,Amazon或Google的某个商用机器学习服务就能把AI转变为产品。

实现一个AI解决方案,除了机器学习,你还需要训练数据,需要human-in-the-loop。缺了训练数据的机器学习就像没汽油的汽车,虽然很贵,但去不到任何地方。缺了human-in-the-loop的机器学习也会导致不良后果。你需要人去推翻机器学习模型低置信度的预测。
所以,如果你是想把AI应用于你的业务的企业高管,那么你想在应该有一个框架了。你可以用AI的7个真相代替AI的7个神话:
真相1:AI=TD+ML+HITL
真相2:AI适用所有企业。
真相3:AI适用现存的小问题。
真相4:算法并不比训练数据的质量和数量更重要。
真相5:机器和人类互补
真相6:AI是机器强化人类
真相7:AI=TD+ML+HITL
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 人工智能
人工智能