
特斯拉4大车祸复盘,图像语义分割或成自动驾驶突破口
今年对于特斯拉公司来说,无疑是个多事之秋。接二连三事故的发生,让人们对辅助驾驶乃至无人驾驶技术产生了质疑。
【编者按】:本文转载自新智元,作者:视觉守望者,编辑:小猴机器人
特斯拉屡次车祸盘点

事故1:2016年1月,在中国京港澳高速上,特斯拉轿车直接撞上前方正在作业的道路清扫车;该清扫车停在最左侧边线上。
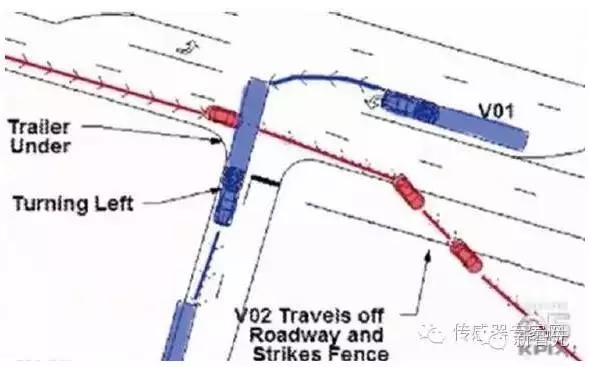
事故2:2016年5月,在美国佛罗里达州北部一个没装红绿灯的十字路口,特斯拉和一辆白色集装箱货车相撞,该货车正在从对向车道进行拐弯操作。

事故3:2016年8月,在德克萨斯州的高速公路上,特斯拉因为未能识别弯道而径自冲出去,从而撞上高速的护栏。

事故4:2016年8月,北京的罗先生刚给新买的特斯拉上完牌照,依然因为未能识别左侧路边临时停靠的小汽车而发生剐蹭。
究其原因
很多文章都对特斯拉传感器的结构布局进行过分析,大抵就是前方侧身和后方侧身的超声波传感器+前方中央的毫米波雷达+后视镜下方的前视摄像头。
·前方侧身和后方侧身的超声波传感器用于检测近距离的障碍物,帮助自动泊车等。
·前视摄像头可以完成路面车道线的检测和障碍物的检测。
·毫米波雷达用于较远距离障碍物的检测。
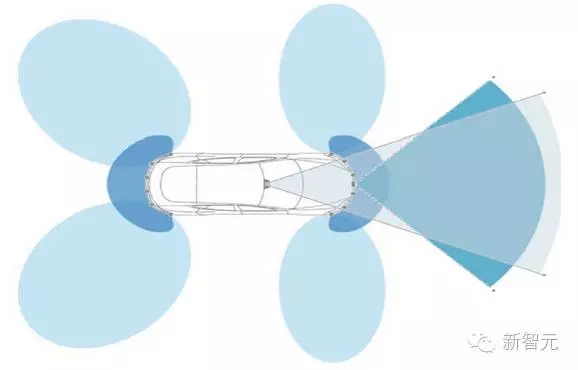
因此碰撞检测主要依赖于毫米波雷达和前视摄像头的协同运作。而前言中事故发生的原因,正是因为这两个模块同时失效引起。总的来说,可能的原因主要有:
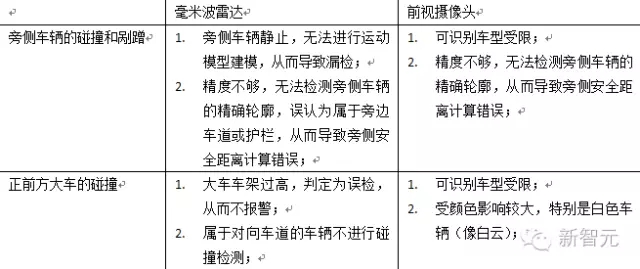
(这里,曝光过强并不被认为是前视摄像头失效的原因,这是因为现在的摄像头基本上都有自动白平衡的功能,可能在某个瞬间会出现全白的图像,但相机很快能够调整回来。)
解决方案
可以看出,特斯拉事故的发生是因为它并没有从人类认知的角度来处理问题,而更像是一个专家系统。特斯拉的Adas系统可以认为属于L2+级别的自动驾驶,即由多个模块捏合而成,包括车道线的检测识别(车道偏离预警LDW),车辆的检测识别(前向碰撞预警FCW),以及某些地面交通标志的检测识别(路径规划和导航)等;上述模块各司其职,互不干涉。下图中不同颜色的标记表示了不同模块的处理结果。

但这种设计理念和人类的认知是截然不同的。从人类角度而言,通常会对整个图像进行理解,也就是利用上下文信息(context)对整个场景进行建模,构成了一个场景模型后再进行相应的处理(碰撞预警、自动巡航等)。下图可以认为是一个常见的场景模型:
·图像上半部分是天空,下半部分是路面,两侧是建筑物;
·中间是可行驶区域以及车道,两侧是行人区域;
·路面和路旁有若干车辆和行人;
·路旁有交通标志。
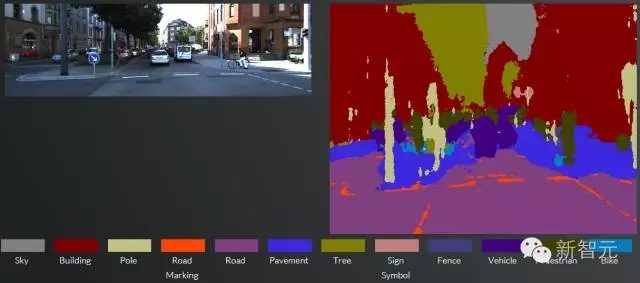
在场景模型中,可以综合考虑各个元素之间的区别和联系,并结合多个传感器和模块的信息,便于各种后续处理。
纵观特斯拉的多次碰撞事故,如果能够建立合适的场景模型,就有可能避免车辆漏检问题的发生。首先,除了利用传统的纹理特征外,还可以根据车辆在图像中的布局、车辆的形状以及和其他元素的位置关系进行判定,从而避免从未见过的车型被漏检。其次,像素级的定位精度能够得到车辆的精确轮廓,这样可以完成准确的旁侧距离计算;同时,检测出来的护栏、车道线和路面等元素可以辅助车辆精确位置的判断。最后,有了对于整个场景的感知,多种传感器和模块可以统一到一个框架下,很容易完成数据的整合工作和交叉验证。
为了理解图像,从而建立场景模型,一种可行的解决方案是对图像进行语义分割。顾名思义,就是将整个场景以像素精度进行语义层面的划分,例如这个像素属于车辆,另外一个像素属于护栏等。从像素折算到物理距离,计算机就可以完成场景的完整建模。
语义分割
那么如何对图像进行语义分割呢?最初的语义分割可以认为是图像分割,就是通过人们设计的一些规则来分离出目标,例如二值化、区域生长、graph-cut等方法。这类方法依据的是目标颜色和背景的差异,或者目标强烈的边缘响应等。但这些都属于人类的理解,因此通常不具备普适性,直到2015年全卷积网络分割(fully convolutional network,FCN)方法的提出。该方法可以被认为是卷积神经网络用于语义分割的鼻祖(该论文获得CVPR2015最佳论文候选奖,相当于XX电影节的最佳提名奖)。
但FCN一个主要的问题就是需要通过池化层对图像进行降维,那么语义分割的结果通常比较稀疏(FCN直接得到的语义分割结果是原始图像尺寸的1/32,改进后的也只能达到1/8)。这对场景建模无疑是致命的,大量的小目标(锥筒、地面交通标志等)和狭长目标(车道线、灯杆等)的丢失会直接造成事故的发生。后续的改进方法都是基于FCN展开,其中SegNet和UberNet是两项对自动驾驶的场景建模具有指导意义的技术。
SegNet技术2015年11月由英国剑桥大学提出,能够很好的解决FCN遇到的问题。从下图可以看出,通过逐层上采样和卷积,SegNet可以得到和原始图像同样大小的语义分割结果,从而保证小目标和狭长目标不会漏检。
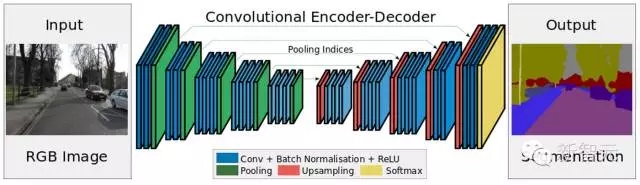
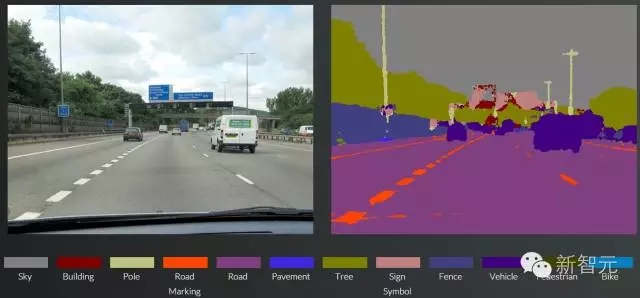
从下图的结果可以看出,灯杆、车道线以及远处的车辆等要素都得到了很好的分割。它一共支持12种目标的语义分割,包括天空、建筑、灯杆、地面标志、路面、人行区、树木、标示牌、护栏、交通工具、行人和自行车,这囊括了大多数自动驾驶场景的元素。
UberNet技术则将语义分割和其他检测识别任务整合到同样一个框架下。这样不仅可以保证计算资源的复用,还利用了任务之间的约束关系帮助优化过程。在下图的结构图中,C1-C6的特征提取结果是复用的。
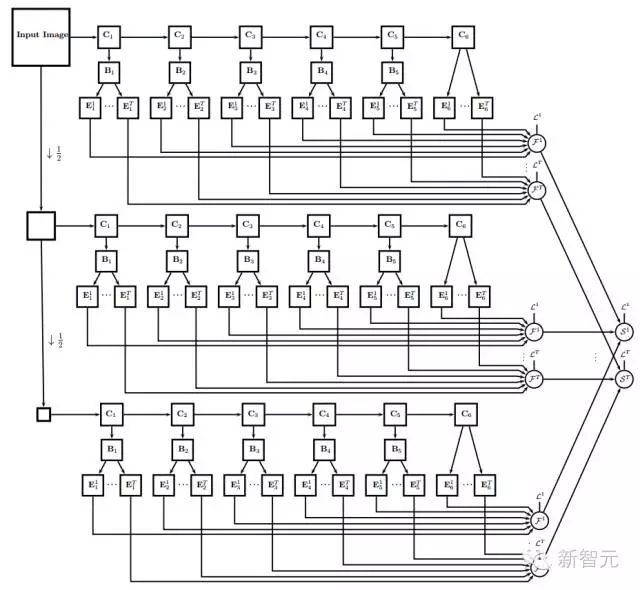
下图给出了UberNet七个任务同时输出的结果。它给自动驾驶的场景建模提出了一个很好的建议,就是可以设计这样一种end-to-end的架构,同时完成语义分割、障碍物检测、车道线检测、路径规划等多个任务。

SegNet和UberNet的提出,使得场景建模成为现实。高精度的语义分割结果+多任务的同步优化,可以以人类的认知方式理解整个世界,一定程度上可以减少或者避免特斯拉碰撞事故的发生。由于数据的原因,这里以发生在中国的事故1和事故4为例:

对于事故1,在场景模型中,可以很好的分辨出前方左侧停靠的清扫车;另外,对于天空、路面、外侧车道线以及护栏的检测识别,能够进一步对障碍物进行校验。

对于事故4,在场景模型中,左侧停靠的汽车并不会发生漏检;在此基础上,利用场景中其他元素进行校验,自动驾驶应该能够成功完成刹车操作。
展望
随着语义分割技术的发展,计算机可以像人类一样对场景有更清晰和完整的建模与认知。在这种情况下,对于车辆等障碍物的检测识别就不需要依赖于某些特定传感器一些规则式的判定了,从而可以避免特斯拉这种事故的发生。但基于深度学习的语义分割技术遇到的问题是高功耗和高计算开销,但这些问题能够随着硬件成本的降低、性能的升级和算法的优化予以解决。可以预见,语义分割会成为辅助驾驶乃至无人驾驶一个重要的组成部分。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 特斯拉
自动驾驶
特斯拉
自动驾驶