
南京大学机器学习与数据挖掘所ECCV16视频性格分析竞赛冠军技术分享
基于第一印象 表象的性格自动分析是计算机视觉和多媒体领域中一类非常重要的研究问题。
英文中有句谚语叫:“You never get a second chance to make a first impression.”(你永远没有第二个机会去改变你的第一印象。)一个人的第一印象可以用来快速判断其性格特征(Personal traits)及其复杂的社交特质,如友善、和蔼、强硬和控制欲等等。因此,在人工智能大行其道的当下,基于第一印象/表象的性格自动分析也成为计算机视觉和多媒体领域中一类非常重要的研究问题。
前不久,欧洲计算机视觉大会(ECCV 2016)ChaLearn Looking at People Workshop 就举办了一场全球范围的(视频)表象性格分析竞赛(Apparent personality analysis)。历时两个多月,我们的参赛队(NJU-LAMDA)在86个参赛者,其中包括有印度“科学皇冠上的瑰宝”之称的 Indian Institutes of Technology (IIT)和荷兰名校Radboud University等劲旅中脱引而出,斩获第一。在此与大家分享我们的竞赛模型和比赛细节。
问题重述
本次ECCV竞赛提供了平均长度为15秒的10000个短视频,其中6000个为训练集,2000个为验证集,剩余2000个作为测试。比赛要求通过对短视频中人物表象(表情、动作及神态等)的分析来精确预测人的五大性格特质,即Big Five Traits,其中包括:经验开放性(Openness to experience)、尽责性(Conscientiousness)、外向性(Extraversion)、亲和性(Agreeableness)和情绪不稳定性(Neuroticism)。视频示例如下所示:

竞赛数据中五大性格特质的真实标记(Ground truth)通过Amazon Mechanical Turk人工标注获得,每个性格特质对应一个0~1之间的实值。

我们的方法
由于竞赛数据为短视频,我们很自然的把它作为双模态(Bimodal)的数据对象来进行处理,其中一个模态为音频信息(Audio cue),另一个则为视觉信息(Visual cue)。同时,需预测的五大性格特质均为连续值,因此我们将整个问题形式化为一个回归问题(Regression)。我们将提出的这个模型框架称作双模态深度回归(Deep Bimodal Regression,DBR)模型。下面分别从两个模态的处理和最后的模态融合来解析DBR。
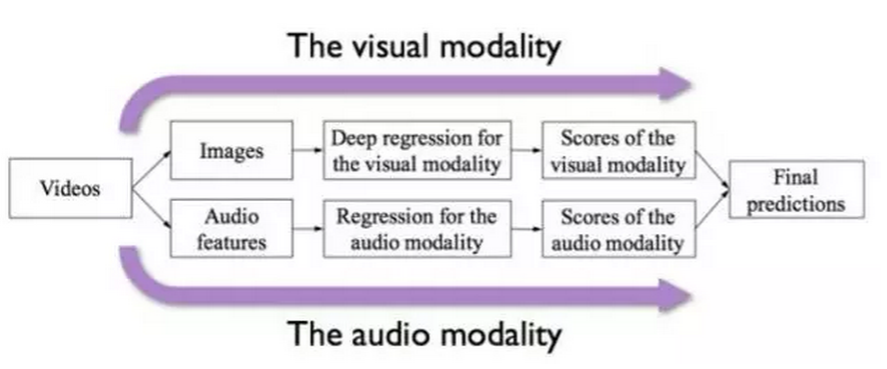
视觉模态
在视觉模态中,考虑到对于短视频类数据,时序信息的重要程度并不显著,我们采取了更简单有效的视频处理方式,即直接将视频随机抽取若干帧(Frame),并将其作为视觉模态的原始输入。当然,在DBR中,视觉模态的表示学习部分不能免俗的使用了卷积神经网络(Convolutional Neural Networks,CNN)。同时,我们在现有网络基础上进行了改进,提出了描述子融合网络(Descriptor Aggregation Networks,DAN),从而取得了更好的预测性能。
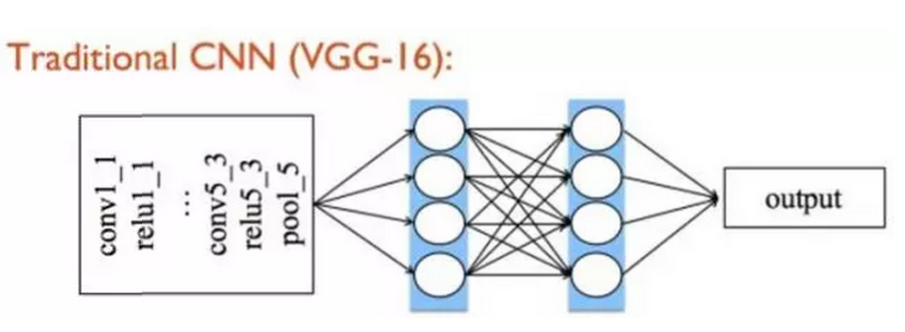
以VGG-16为例,传统CNN经过若干层卷积(Convolutional)、池化(Pooling)的堆叠,其后一般是两层全链接层(Fully connected layers)作为网络的分类部分,最终输出结果。
受到我们最近工作[2]的启发,在DBR视觉模态的CNN中,我们扔掉了参数冗余的全链接层,取而代之的是将最后一层卷积层学到的深度描述子(Deep descriptor)做融合(Aggregation),之后对其进行L2规范化(L2-normalization),最后基于这样的图像表示做回归(fc+sigmoid作为回归层),构建端到端(End-to-end)的深度学习回归模型。另外,不同融合方式也可视作一种特征层面的集成(Ensemble)。如下图,在DAN中,我们对最后一层卷积得到的深度描述子分别进行最大(Max)和平均(Average)的全局池化(Global pooling)操作,之后对得到的融合结果分别做L2规范化,接下来将两支得到的特征级联(concatenation)后作为最终的图像表示(Image representation)。
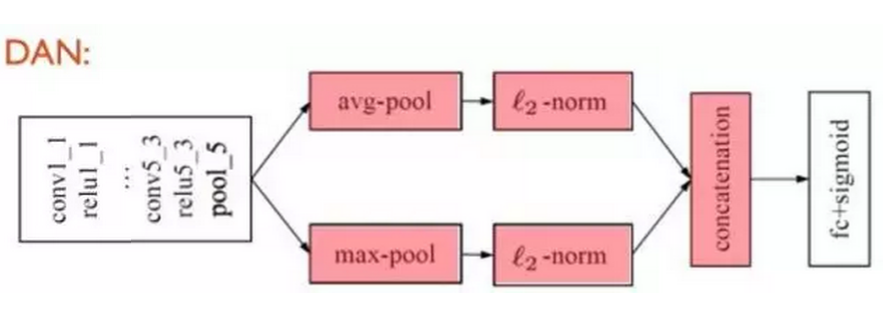
传统CNN中,80%的参数存在于全链接层,而DAN摒弃了全链接,使得DAN相比传统CNN模型拥有更少的参数,同时大幅减少的参数可加速模型的训练速度。另外,全局池化带来了另一个优势即最终的图像表示(512维)相比传统全链接层(4096维)有了更低的维度,有利于模型的可扩展性以处理海量(Large-scale)数据。
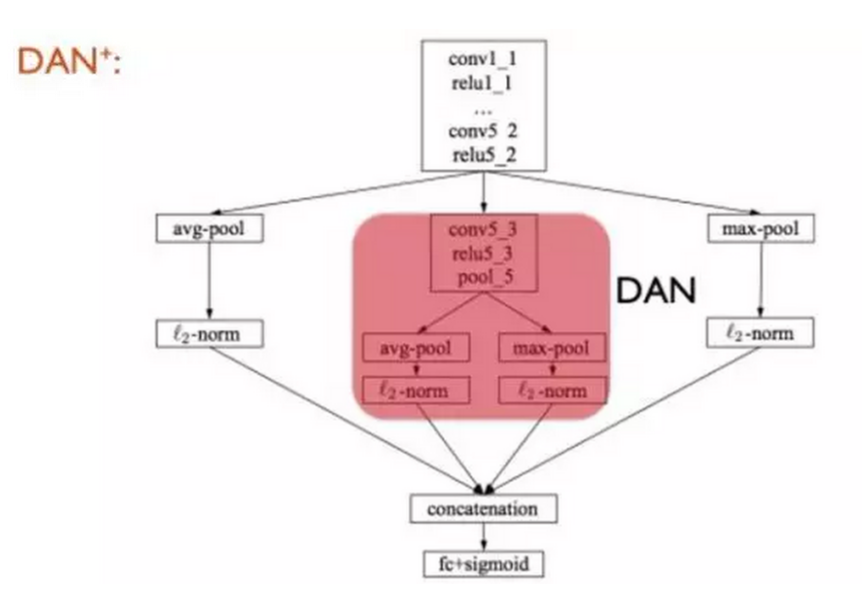
此外,为了集成多层信息(Multiple layer ensemble),在DAN基础上我们提出了可端到端训练的DAN+。具体而言,是对ReLU5_2层的深度描述子做上述同样操作,得到对应于 ReLU5_2的图像表示,将其与Pool5层的DAN得到的图像表示进行二次级联,最终的向量维度为 2048 维。
除DAN和DAN+外,在视觉模态中,我们还利用了著名的残差网络(Residual Networks)作为模型集成的另一部分。
音频模态
语音处理中的一种常用的特征为MFCC特征,在竞赛模型中,我们首先从视频中提取原始语音作为输入数据,之后对其抽取MFCC特征。在此需要指出的是,抽取MFCC过程的一个副产品是一种名为logfbank特征,如下图所示:
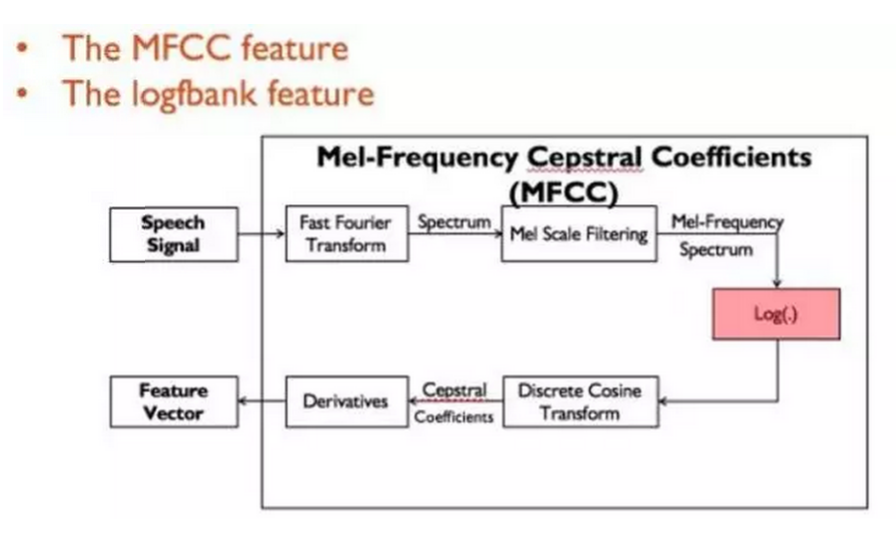
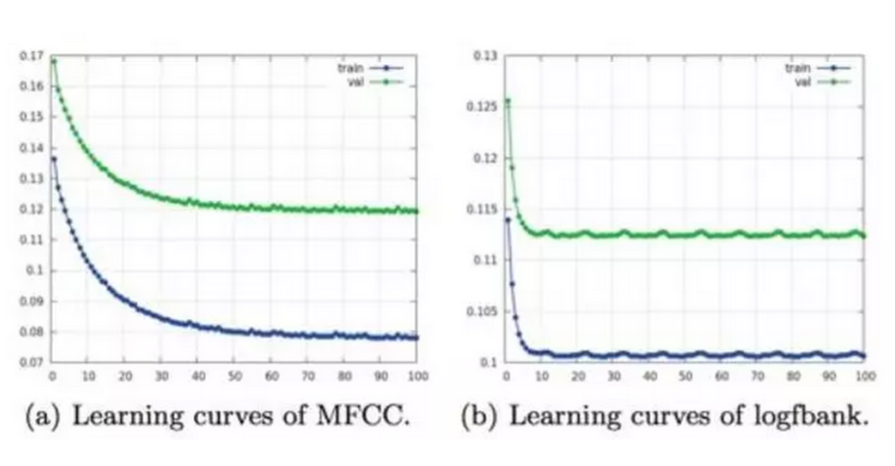
在抽取logfbank和MFCC特征后,我们同样采取mini-batch形式的训练方式训练线性回归器(Linear regression)。在竞赛中,我们发现logfbank相比MFCC有更优秀的预测效果,如下图所示。其纵轴为回归错误率(越低越好),其横轴为训练轮数,可以发现logfbank在最终的回归错误率上相比MFCC有近0.5%的提升。
于是我们选取 logfbank特征作为音频模态的特征表示以预测音频模态的回归结果。由于竞赛时间和精力有限,我们在比赛中未使用语音处理领域的深度学习模型。不过,这也是后续可以提高模型性能的一个重要途径。
模态融合(Modality ensemble)
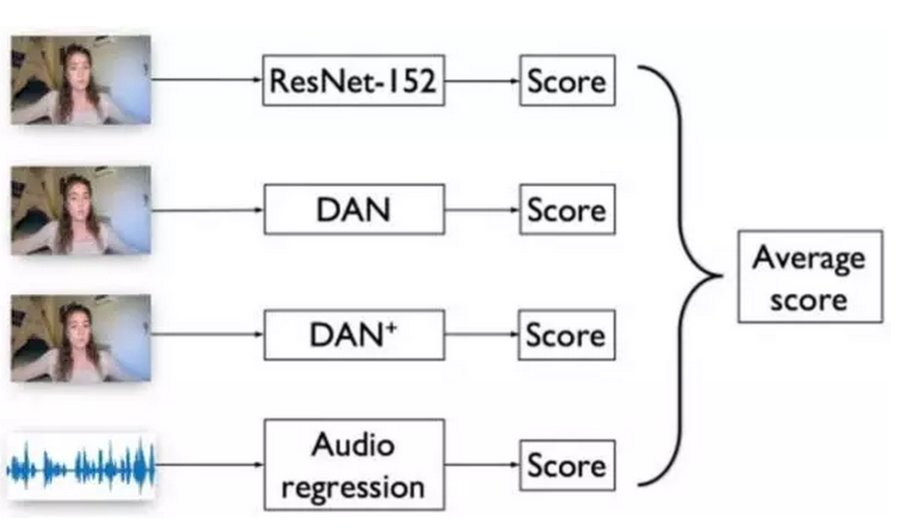
待两个模态的模型训练完毕,可以得到不同模态不同模型的性格特质预测结果,比赛中我们将其无权重的平均作为该视频最终的性格特质预测结果,如图:
竞赛结果
比赛中,我们对一个视频抽取100 帧/张图像作为其视觉模态的输入,对应的原始音频作为抽取logfbank特征的语料。训练阶段,针对视觉模态,其100张图像共享对应的性格特质真实标记;预测阶段,其100张图像的平均预测值将作为该视频视觉模态的预测结果。
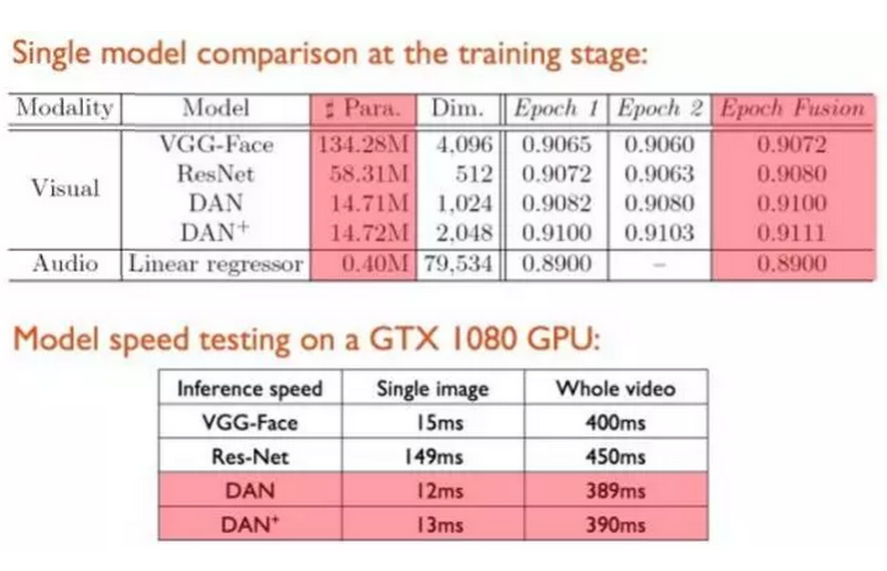
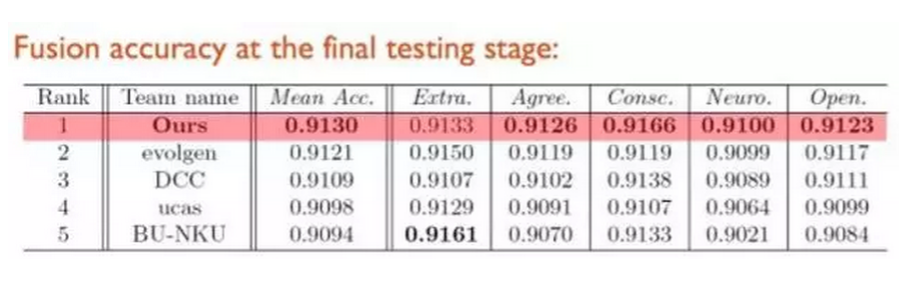
经下表对比,可以清楚看到,DAN相比VGG-Face,由于没有了冗余的全链接层,其参数只有VGG-Face的约十分之一,而回归预测准确率却优于传统VGG模型,同时特征维度大大减少。此外,相比ResNet,我们提出的模型DAN和DAN+也有不俗表现。此外,在模型预测速度上,DAN和DAN+也快于VGG和ResNet。
模态集成后,我们在五个性格特质预测上取得了四个结果的第一,同时我们也取得了总成绩的冠军。
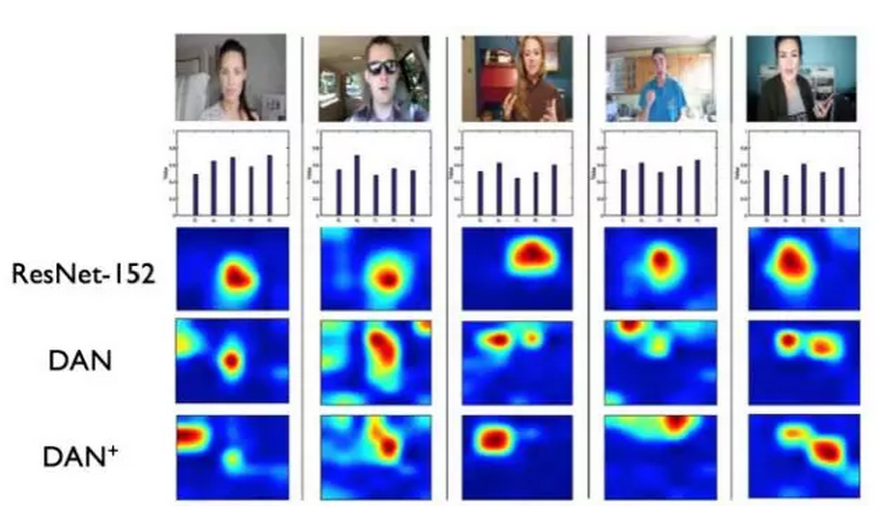
模型分析
最后,我们将模型最后一层卷积/池化的特征做了可视化。可以发现ResNet仅仅将“注意力”聚焦在了视频中的人物上,而我们的DAN和DAN+不仅可以“注意”到人,同时可以将环境和动作信息结合起来进行表象性格预测。另外值得一提的是,其余参赛队均做了人脸检测等预处理操作,从而将人物从视频中“抠”出,但是这样的操作反而降低了整个性格特质预测的性能。俗话说“气由心生”,一个人所处的环境(尤其是卧室、办公室等私人场所)往往可以从侧面反映一个人的性格特性。
参考文献
[1]Victor Ponce-Lopez, Baiyu Chen, Marc Oliu, Ciprian Cornearu, Albert Clapes, Isabelle Guyon, Xavier Baro, Hugo Jair Escalante and Sergio Escalera. ChaLearn LAP 2016: First Round Challenge on First Impressions - Dataset and Results. European Conference on Computer Vision, 2016.
[2]Xiu-Shen Wei, Chen-Wei Xie and Jianxin Wu. Mask-CNN: Localizing Parts and Selecting Descriptors for Fine-Grained Image Recognition. arXiv:1605.06878, 2016.
[3]Chen-Lin Zhang, Hao Zhang, Xiu-Shen Wei and Jianxin Wu. Deep Bimodal Regression for Apparent Personality Analysis. European Conference on Computer Vision, 2016.
【编者按】本文转自新智元。来源:深度学习大讲堂,作者:魏秀参
作者简介:魏秀参,为本次竞赛NJU-LAMDA参赛队Team Director。南京大学计算机系机器学习与数据挖掘所(LAMDA)博士生,研究方向为计算机视觉和机器学习。曾在国际顶级期刊和会议发表多篇学术论文,并多次获得国际计算机视觉相关竞赛冠亚军,另撰写的「Must Know Tips/Tricks in Deep Neural Networks」受邀发布于国际知名数据挖掘论坛 KDnuggets 等。 微博ID:Wilson_NJUer
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 大数据
机器学习
硬科技
大数据
机器学习
硬科技