
看Deepmind机器人尬舞,边玩边学AI技术
Deepmind通过增强学习让木偶学习行走、跑跳。
在自然界中,无论是动物,还是人类,都可以灵活而随心所欲地做出一些动作,比如猴子在树上自由自在得摆动,或是NBA球员虚晃过对手,帅气地投出篮球。但是在AI 研究领域,想要让机器人掌握这些动作(物理上就是一种复杂的电机控制)却不是一件容易的事,而这是AI研究领域的重要组成部分。
近日,Deepmind公布了智能电机的相关研究成果,展示了机器人学习如何控制和协调身体来解决在复杂环境中的任务。这一研究涉及不同领域,包括计算机动画和生物力学。
接下来我们带领大家边玩边学。
在复杂环境中产生动作行为
上一个小视频,先睹为快
此刻,想必你已经忍俊不禁了吧。视频中,我们可以直观感受到木偶的动作是笨拙的。
此处采用的是增强学习,但不同于Deepmind此前开发的Atari或Go,这里,需要准确描述复杂行为。具体来说,就是奖励机制的不同,在Atari和Go的开发过程中,设计人员将得分作为奖励,就可以依照预期来优化系统。但是在连续的控制任务(如运动)中,奖励信号的选择就没有那么容易,常常会出现奖励信号的选择不当,从而导致优化结果与设计师期望不符。
由此,自然就会想到慎重选择奖励信号,以此来实现优化,但是如果谨慎设计奖励,也就等同于回避了增强学习的核心问题:系统如何直接从有限的奖励信号中自主学习,让木偶实现丰富而有效的动作行为。
研究团队表示,为了让系统有自我学习的能力,他们选择直面增强学习中的核心问题。于是团队以环境本身具有足够的丰富性和多样性为研究的主要背景,从两方面实现学习:
一:预设一系列不同难度级别的环境,引导木偶学习和找到解决困难的方案;
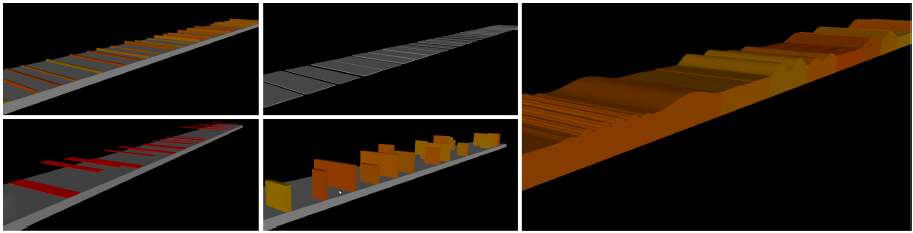
二:因为过拟合,奖励机制和动作细节都具有一定的误差,从而每一次运动都有些微不同。发现不同方案之间的特殊性能差距,也将帮助系统有效学习。

为了使操控的木偶面对不同的地形有效的学习,研究团队还开发了增强学习算法。
首先,团队开发了强大的策略梯度算法,如信任区域策略优化(TRPO)和近端策略优化(PPO),其中,他们选择将每次更新的参数绑定到信任区域以确保算法的稳定性。
其次,对于像广泛使用的A3C算法以及相关算法,他们将其分配运用在许多并行的代理环境和实例中。
这样,面对复杂的环境,通过自主学习,木偶自然就会有丰富而有效的行为表现。
通过对抗模仿人类行为
再来看看下面的“群魔乱舞”
视频中这些小人们是不是已经不忍直视,不过专业的角度来看,技术上已经很棒了。
据了解,构建可编程人形木偶的问题可以追溯到几个世纪以前。在1495年,达芬奇以装甲骑士的形式构建了一个人形自动机。骑士能够通过曲柄传递的力量挥动,坐起来,打开和关闭其下巴。不像大多数钟表只能产生沿着单极循环的运动,机械骑士可以重新编程以改变其运动,从而能够及时改进手臂运动方向或交替运动顺序。
现如今,在此系统中,最优控制和增强学习能够用来设计人形木偶的行为,并且神经网络能够存储动作行为和灵活检测多种运动模式,将这几种技术融合,可实现运动控制。但研究团队表示,依靠纯增强学习(RL),会使运动行为过于刻板,不符合设计期望。
通常,在计算机动画相关文献中使用的替代性方案是采取运动捕捉数据,将其加载到控制器中。在视觉上,采取这一方案的方法都产生了让人满意的运动表现,然而,其中有些方法产生的状态序列仅仅是理论上的,物理上并不适用。还有一些方法需要设计大量的组成因素,如成本函数。
而此处,为了从运动捕捉数据中进行仿制学习,研究团队采用生成对抗模仿学习(GAIL),这是模仿学习中最近的一项突破,简言之,该方法就是以类似于生成对抗网络的方式产生模仿策略。与已存在的模仿学习相比,该方法的主要优点是模仿与演示数据之间相似度的衡量不是基于预先设计好的度量值。
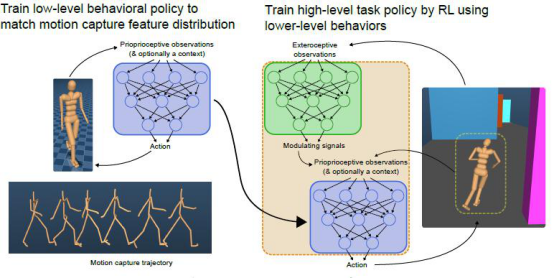
具体操作上,主要就是先训练低级别控制器,通过使用GAIL的扩展来从运动捕捉数据中生成行为信号,接着将低级别控制器嵌入更大的控制系统中,其中高级别控制器通过RL学习调制低级别控制器来解决新任务。
显然,通过对抗模仿学习,人偶会有更加灵活的身手。
强大的模仿能力
据悉,该系统的具体实现主要基于一种生成模型的神经网络架构,它能够学习不同行为之间的关系。
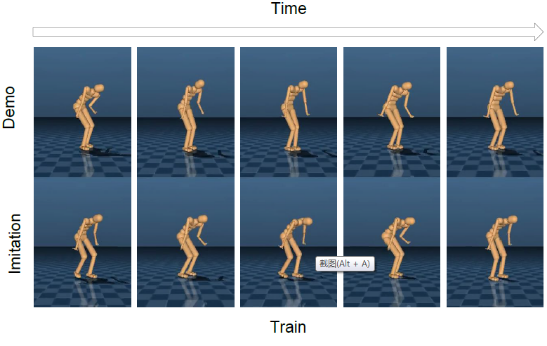
首先,给其一个基本动作,通过训练,该系统可以自动对最基本动作进行编码,并且基于基本动作及对抗学习,系统自动微小改变来创新一个新动作。同时,研究团队还表示他们的系统可以在不同类型的行为之间切换。
总结
实现系统的灵活性和适应性是AI研究的关键因素,Deepmind研究团队直面困难,专注于开发灵活的系统,虽然目前系统模型依然粗糙,但是我们还是很期待后期进一步的优化和改进后的成果。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 人工智能
深度学习
神经网络
人工智能
深度学习
神经网络