
腾讯AI翻译首次亮相博鳌论坛,只证明了这一件事……
不管是技术层面,还是训练数据,当前的AI翻译距离取代人类还有好一段距离。
“一带一路”=“一条腰带和一条路”?
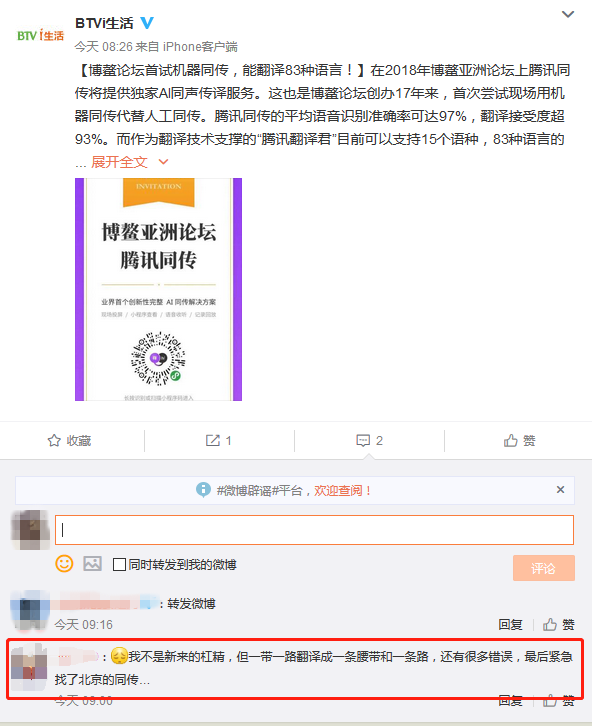
这是博鳌论坛首次采用AI同声传译技术,作为头一份的“腾讯同传”竟然还出现这种离谱的翻译错误。
另外,从网上一些上传的现场翻译图片来看,一些错误简直令人不忍直视:

按照官方所称,上面的错误简称“大面积单词无意义重复、大小写及字符混乱”。
首次亮相结果闹乌龙,说好的取代人类呢?
在博鳌论坛现场,基于自研的NMT(神经网络机器翻译)、语音识别等技术,“腾讯同传”会实时识别、翻译各国嘉宾的演讲内容,并同时以中英双语的字幕形式进行投屏展示。另外,观众还可利用微信小程序对嘉宾演讲的双语同传内容进行回看、收听和记录。
从提供的服务内容来看,腾讯的同声传译听起来还是不错的。然而,从上面的错误来看,体验有些糟糕呢。
对此,也有网友也进行了调侃:
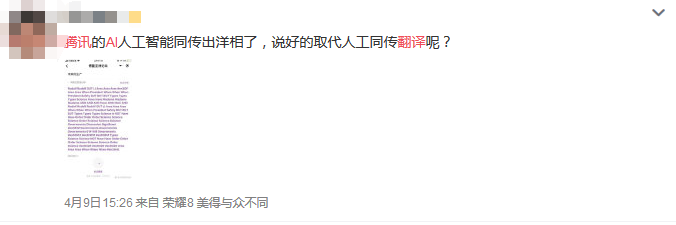
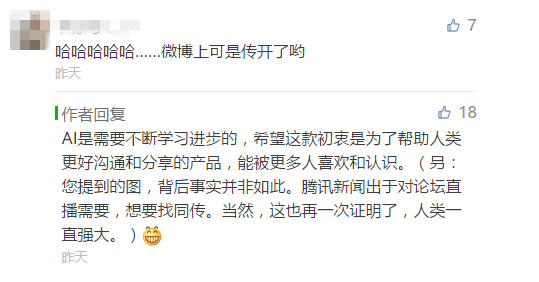
对于此次乌龙,腾讯官方也没有试图遮掩,并针对图片中“大面积单词无意义重复、大小写及字符混乱”的错误给出了解释。
譬如中英双语切换频率的问题,官方解释:
当声源在两种语言之间不断转换时,后台中、英文识别引擎就会同时开始工作,这会导致两种识别引擎互相“掐架”,而翻译结果却只能选择一种语言进行输出,再加上对嘉宾每个语气词也做了精准的啊啊啊翻译,导致引发错误。
又比如“for”的问题,官方称:
出现这种情况主要是包括神经网络机器翻译在内的深度学习算法,在原理上或多或少都有一定不确定性,在特定的情况下有一定的概率引发翻译偏差。今天的嘉宾演讲内容中包含“for for for for”、 ”that’s that’s that”等重复内容,而翻译引擎不巧放大了这个重复,导致了翻译结果出现错误。

AI同声传译的玩家不在少数,闹乌龙的也不止腾讯一家
目前,包括腾讯在内,涉及AI同声传译市场的玩家也不在少数,比如科大讯飞、搜狗、百度等公司。
在市场的玩法上,他们的套路基本可以分为两种,一类是以翻译APP、API接口形式存在的软件产品,譬如此次腾讯参加博鳌论坛的产品;另一类则是AI同声传译硬件产品,最为典型的代表就是科大讯飞的“晓译翻译机”,以及搜狗的“搜狗旅行翻译宝”。
从网上的一些用户体验来看,再结合此次腾讯同声传译的情况,我们只能说,会闹乌龙的不只是腾讯一家。
以科大讯飞的晓译翻译机为例,有网友以几句英语教学的录音来进行测试,如下:
According to our records, a room for two guests was booked under your name.
谷歌:根据我们的记录,有两位客人的房间是以您的名义预定的。
讯飞翻译机:根据我们的房间记录,两位客人,你们的名字都是什么?
Today we have grilled tuna and New York strip steak served with creamy Italian herb sauce.
谷歌:今天我们有烤金枪鱼纽约牛排配奶油意大利香草酱。
讯飞翻译机:吉姆去纽约的牛排,配有干净的意大利香草酱 / 蒂姆已经得到了一份纽约的牛排,用来清洁意大利的泥土沙司。
又比如搜狗的旅行翻译宝,在正常的翻译过程中,其也是偶有错误,而在对话内容较为复杂,或者语速过快等场景下,它的语音识别也会出现问题,之后的AI翻译自然是无法理解。又比如阿里巴巴的AI系统,此前的一场云栖大会中,该系统直接将“nationally”翻译成了“男生弄乱”,让演讲者马云爸爸在现场呆愣了5秒。

最后:AI翻译还处于初期发展阶段,想要取代人类还很早
当前,国外的谷歌、微软,国内的BAT、科大讯飞、搜狗等公司均在加紧布局AI翻译市场,发布各类软硬件产品。在技术层面,NMT是多个公司在AI翻译产品中所采用的技术,其能够模仿人脑神经思考的模式进行翻译。不过,腾讯方面此次的回应则表明,技术依旧存在不确定性的。
不仅仅是技术,AI翻译的训练数据也跟不上了。在一些AI速记的应用场景中,我们能够看见,为了保证现场实时速记的准确率,工作人员一般都会提前用大量针对性数据来对系统进行训练。
比如此次闹出乌龙的腾讯,在备战期间,“腾讯同传”也学习了该论坛过往数百份演讲稿。然而,从现实情况来看,训练的数据依旧是不够的,毕竟连“一带一路”这一固定词汇都能翻译错误。
遥想此前,包括腾讯在内,在发布AI翻译产品的时候都以“替代人类翻译员”为自己的标语。不过,从现实情况来看,技术依旧存在不确定性、数据欠缺。这只能证明一件事,AI翻译想要取代人类翻译员,还有一段路要走。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 AI翻译
人工智能
博鳌论坛
腾讯
AI翻译
人工智能
博鳌论坛
腾讯