
第一批被AI累死的人
“有多少智能,就有多少人工。”这似乎是AI进化必须经历的过程。
一双眼睛的局部细节图出现在电脑屏幕上,小慧对着放大的眼睛,一步步地做好标记点。
一眼望过去,一排排的电脑屏幕上,都是类似的画面。也许是因为窗帘的遮光效果太好,略显昏暗的办公环境加上电脑屏幕上被放大的各种物体细节,颇为惊悚。
在某人工智能研究院看到这一幕,不觉惊叹即使是头部的AI创业公司,最关键的一环依然是从数据标注员开始的。
而这是一群被称作第一批被AI累死的人。
AI的老师:画框的这些人
伴随着AI兴起的最关键的技术莫过于深度学习,作为深度学习的基础,神经网络是一种以输入为导向的算法,其结果的准确性取决于接近“无穷”量级的数据。
所以摒除那些复杂的中间环节,深度学习最关键的就是需要大量的数据训练,这也是为什么在互联网大数据的时代,AI可以崛起。而在数据训练之前,又必须先对大量的数据进行标注,作为机器学习的先导经验。
因此,催生了大量数据标注员的产生。
简单的说,数据标注员类似于AI的老师,举个形象的例子,我们要教机器认识一个苹果,你直接给它一张苹果的图片,它是完全不理解的。我们得先有苹果的图片,然后在上面标注着 " 苹果 " 两个字,机器通过学习了大量的图片中的特征,这时候再给它任意一张苹果的图片,它就能认出来了。
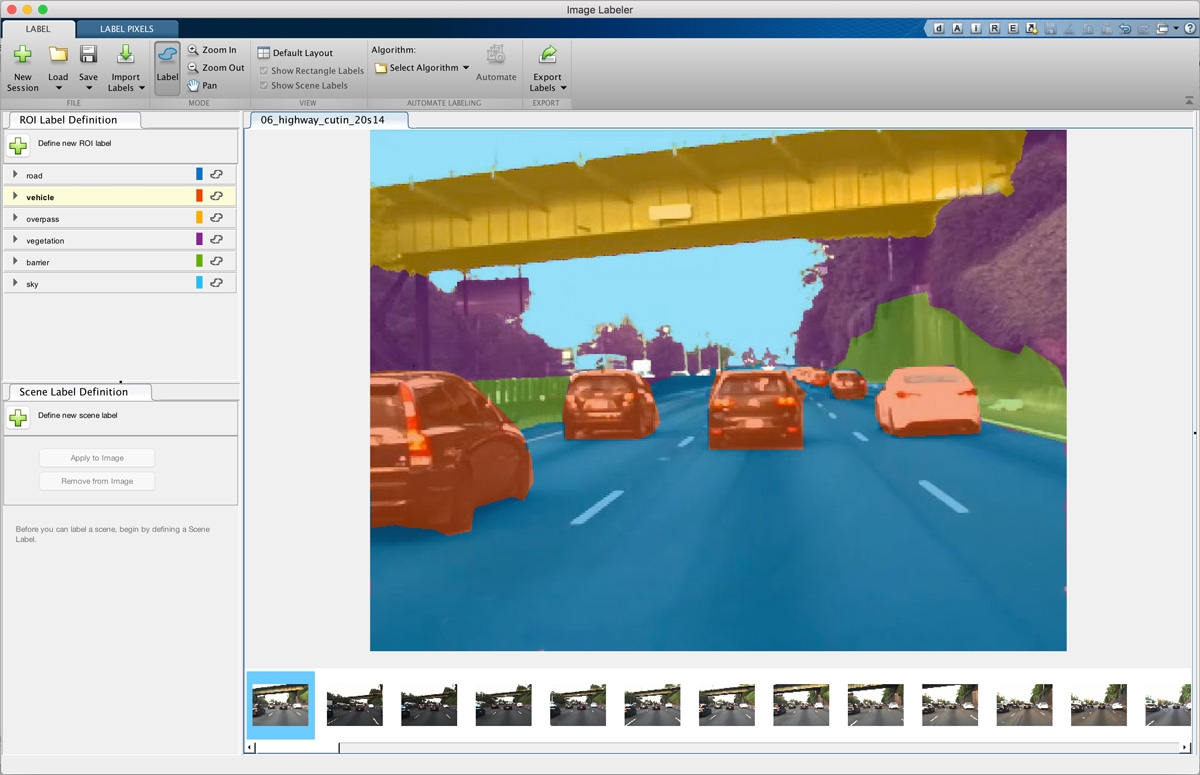
据了解,目前标注员的工作内容常见的有拉框标点、打标签、分割、批注等等。其中分类就是最常见的打标签,比如标注画面上动物毛发颜色、动物耳朵等等;框选是将画面中相对应的对象标框标注;还有一种是描点标注,一般用于更细致的人脸标注:需要在眉毛、眼睛、鼻子、嘴巴等关键点做二十多个标记点。
从他们的基本工作内容就可以看出来,数据标注是个非常枯燥而又考验人耐力的工作,并且相比较AI所代表的高科技,标注看起来毫无技术含量。
一条产业链的开始
但巧妇难为无米之炊,AI算法的训练离不开这些大量的数据标注,与之相伴生的数据标注外包业务也成了热门的产业。
在IT桔子的大数据标注公司专辑中,一共收纳了6家,其中,有5家都在2017年到2018年这个时间周期内获得千万的融资:
2017年7月,BasicFinder完成1000万人民币Pre-A轮融资;
2017年11月,龙猫数据获得A轮3370万人民币融资;
2018年1月,星尘数据获得1000万人民币Pre-A轮融资;
2018年3月,爱数智慧获得A轮融资;
2018年5月,周同科技完成2000万人民币A轮融资。
同时,他们业务方向也有一定细分区别,有的以处理图像见长,有的数据标注公司更擅长做一些视频标注。而这些公司的服务企业有百度、小米、京东、今日头条这样的互联网公司,也有出门问问、云从、深鉴等AI公司。
另外,像京东、百度、腾讯、阿里其实都有自己的标注平台和工具。
而在国外方面,亚马逊有推出众包数据平台Amazon Mechanical Turk,初创公司方面则有CrowdFlower、Mighty AI等。
这些已经算是这个领域的佼佼者了,在他们的下面,还有成百上千的小的数据标注公司。
据悉,数据标注行业实行这样一套分工流程:上游的科技巨头把任务交给中游的数据标注公司,再由中游众包给下游的小公司、小作坊,有的小作坊还会进一步众包给“散兵游勇”,比如学生或家庭主妇。
这条产业链上,分包现象越严重,最终落到最底层的数据服务公司的价格就越低,一层层的“数据黄牛”压缩了利润空间,所以一些任务经过数手转包,酬劳已低得惊人。
目前的数据标注工作主要是集中在河北、河南、山东、山西等劳动力密集的地区,这样的选址也因为能够以更加低廉的劳动力成本去完成大量的数据标注工作。
在很多数据标注的报道中,出现频率最高的都是那些毕业于职业技术学校的学生,他们在三四线城市,只需要会操作电脑,就能做数据标注的工作。然而枯燥而又乏味的重复性工作,导致数据标注人员的流动性非常之大。此前,在澎湃新闻的一篇视频采访中,某数据标注公司创始人表示他们有500名左右的在职人员,但是全职的只有11、12个。
在一些大的数据服务公司,他们宣称平台用户(数据标注人员)超过20万人,其中很多都是兼职人员。
不过,快速的人口流动也依然阻挡不了低门槛数据标注生意的红火。
有多少智能,就有多少人工
即使现在有一些数据服务平台开发了AI工具来辅助人工标注,但依然需要数据标注员去检查和修正其中的错误。在一些专业数据标注公司,机器占30%,而人工标注占比达到70%左右。
梳理数据标注员的工作逻辑,就像一个悖论,AI能否进化的更为智能某种程度上取决于这些标注工作的人,而这个工作却是最不智能、最没有技术含量的。
记得在一篇采访中,管理标注员的负责人用特斯拉(Tesla)的自动驾驶事故给员工“打鸡血”,他提到2016年,一辆自动驾驶模式下的特斯拉发生车祸事故。事后特斯拉公司发表声明称:白色卡车在蓝天背景下识别不出来,特斯拉因此没有启动刹车。
“我一直跟他们说:‘你们打磨的每一个数据都会为人工智能做出巨大贡献,将来的无人驾驶车能够识别出蓝天下的白色卡车,就是因为你当年把它标出来了。’”

这种看似无意义的低效率工作应该由AI去做才符合我们对技术的认知,因为我们发展人工智能的初衷,就是为了解放生产力、提高生产效率。
最需要AI去做的事情,AI反而无能无力,而我们为了能让AI取代劳动密集型的工作,得先为AI服务,付出密集、辛勤的劳动,这让数据标注工作看上去有点赛博朋克、反乌托邦的“魔幻”感觉。
然而更令人觉得沮丧的是,人工去训练AI依然存在很多问题。
此前,清华大学人工智能学院院长张钹院士就提到纯数据驱动的系统也存在很大问题——鲁棒性很差,易受到很大的干扰。即便训练出的系统模型准确率高达99%,但在实际应用中,仍然会犯很多“弱智”的错误。
这就陷入了死循环,人不可能像AI一样,在工作中严格按照数据程序毫无瑕疵地完成工作,纰漏或者技术本身的问题,会导致人工智能的不准确性。最终,就在这个无限循环中不停地优化。
而且考虑到数据的隐私和公司的商业利益,同类型的数据是无法相互打通的,就像一位数据标注资深从业者所说, “以自动驾驶领域的数据标注为例,我用A公司的数据模型放到 B公司的设备上跑不通,甚至摄像头换了一个角度、位置或分辨率,都跑不通。”
“有多少智能,就有多少人工。”这似乎是AI进化必须经历的过程。
结语:
当然,最完美的情况应该是:AI能够自己消化大量的数据自学成才。目前无需标注数据的无监督学习已经从实验室走向应用,而类似的迁移学习算法也能减少一定的数据标注工作量。
Facebook人工智能研究部门负责人Yann LeCun曾经说过,AI的核心在于预测,AI的下一个变革是无监督学习、常识学习。研究人员正努力让 AI 不依赖人类训练,自己去观察世界是如何运转的,并学会预测。
所以理想环境下,可能我们探讨的悖论过几年或者十几年就能完美解决了,这批为AI服务最终会被AI取代的人,也“功成身退”了。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 人工智能
人工智能