
你的人脸数据都去了哪儿?
人脸数据收集容易,监管却是难上加难。
在AI换脸软件ZAO和旷视校园人脸识别的风波后,17万人脸数据被公开挂在网上商城出售的消息“接踵而至”,人脸突然成了“危险品”。
无处不在的人脸识别,当采集人脸数据的渠道越来越广,很多人会疑惑,我们的人脸数据最终都流向了哪里?
在刷脸解锁手机,付款,进出入高铁站、机场的时代,你的脸可能在研究人员的数据集中,也可能在暗网的黑产交易中,也可能被Deepfake后换到了另一个身体上……
人脸数据都去了哪儿?数据集或成为隐患
AI时代下,科技公司会通过数十亿张人脸图片的训练来改进面部识别算法,你的脸很有可能就是“训练样本”之一,那么软件公司又通常从哪些渠道获取人脸图像“喂养”自家的算法呢?
早年,人脸识别还没有进入到深度学习的阶段,人脸数据收集还是打着隐私的烙印,研究人员需要获得志愿者同意,才能采集人脸数据纳入到数据库中。比如早期由耶鲁大学计算视觉与控制中心创建的Yale人脸数据库,只包含了15位志愿者的165张图片。
但是到了后期,尤其是深度学习技术的快速应用普及,几百张志愿者的人脸对于数据训练来说只是杯水车薪,人脸数据的收集也开始走向不可控。
人脸数据集通常情况下是为图像识别赛事准备的,比如微软的MS Celeb 1M,这个由微软在2016年发布,包含了10万个名人,近1000万张面部图片的数据库,就是用来服务当时最高水平图像识别赛事之一的MSR IRC。

同样还有业界“黄金标准”之称的人脸识别算法测试FRVT,其背后由美国国家标准与技术研究院(NIST)提供人脸数据集支持。
此时以学术研究为目的的人脸数据集还处在可控范围内,但是到了后期,谁也无法控制这些人脸数据到底被用作什么,数据训练之外,它又流向了哪里?
如果我们在搜索引擎里键入关键词“人脸数据集”,会发现海量的人脸数据库可以被下载获取,就像在网上下载资源一样,轻点一下,跳转到下载软件,几个G的人脸数据包就“属于”你了。
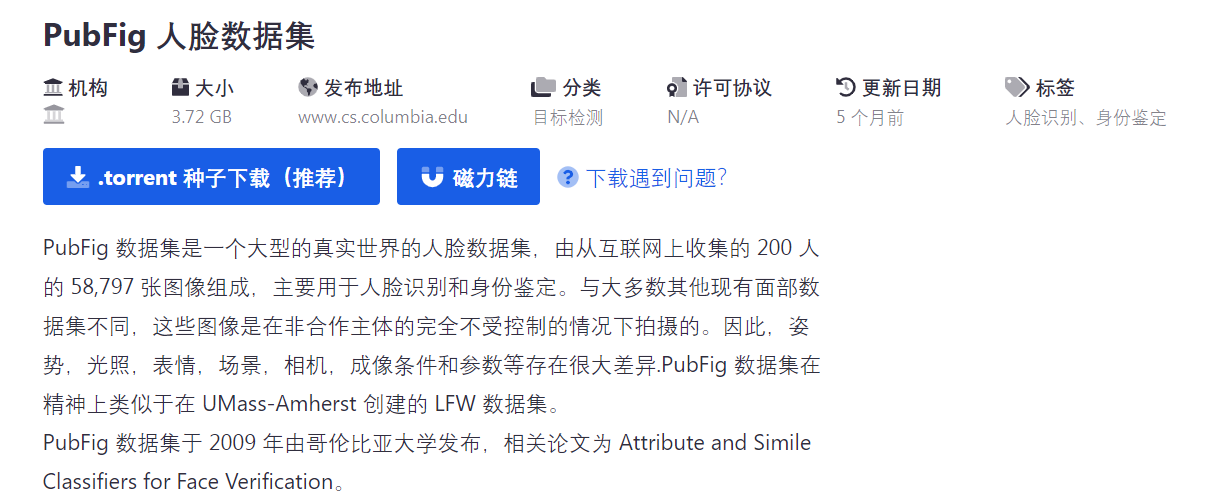
成千上万张被标记的人脸数据,如此轻易被获得,细思极恐。问题随之而来,数据集中的人脸到底从何而来?
镁客网粗略统计了几个包含人脸数据较多,且常用的人脸数据集,从发布机构来看,多为科技公司和高校,获取渠道有三个:1、爬取互联网数据;2、源自雅虎旗下网络相册Flickr;3、新闻机构、商业公司等。
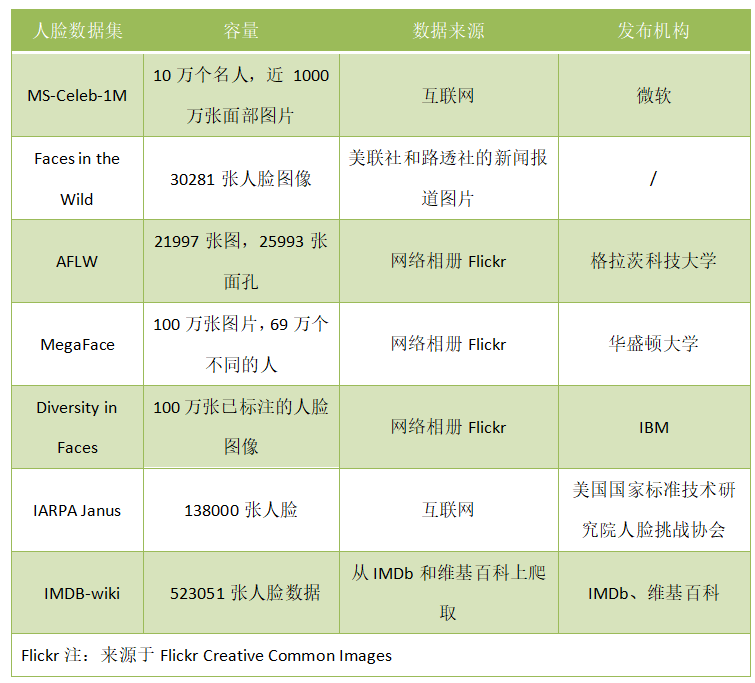
这些人脸数据集有的已经做好标注,囊括了人脸关键点检测、人脸表情、人脸年龄和性别、人脸姿态等信息。
多数数据集在开放的时候,都会写上不可商用的补充协议,强调是在知识共享许可(CC协议)下抓取和搜索图像,根据CC协议中:照片可以重新用于学术研究,但照片中的人物并不一定授权许可,而是版权所有者授权。然而数据集公布后,发布机构也无法掌管它的使用。

不然,微软也不会在被媒体大面积曝光后,悄悄地删除了这个世界上最大的公开人脸识别数据库。之后另外两个学术单位也删除了相关的数据集:分别是杜克大学的Duke MTMC监控数据集,和斯坦福大学的Brainwash数据集。
当初衷是为了推动学术研究的人脸数据集,都有被商用以及滥用的风险,更何况那些源自其他渠道的人脸数据。
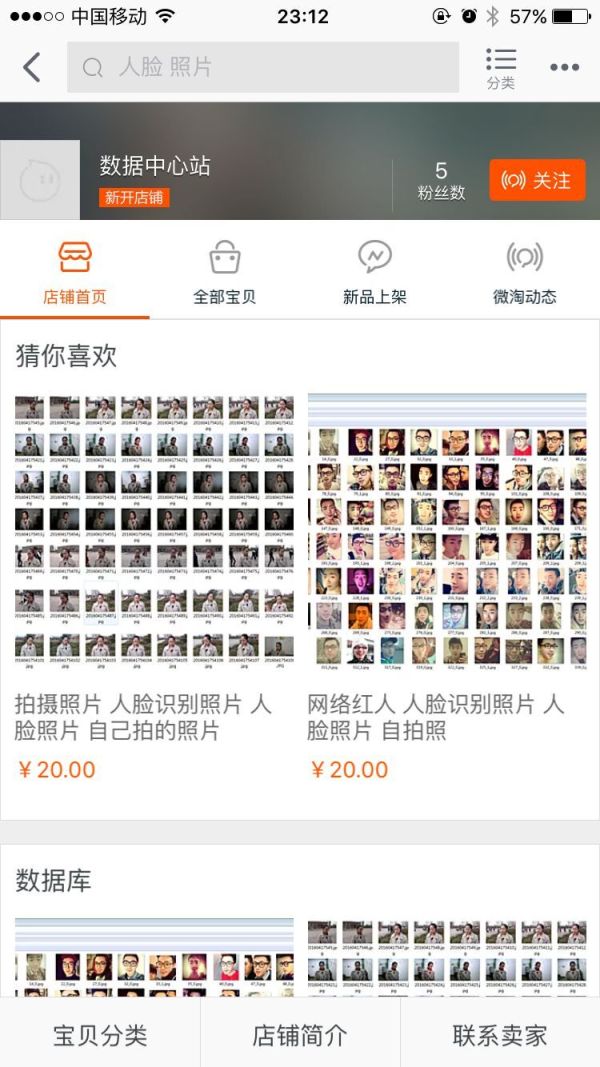
以人脸数据买卖为例,早在2016年,知乎上就出现了网友在淘宝买人脸数据的话题。除了网上商城之外,人脸数据也可以从售卖面部数据的商业公司处获得,比如一家名为Vigilant Solutions的公司就提供1500万张面孔,可以用来“解决”人脸识别软件训练的难题。
至于这些人脸又源自哪里,恐怕和上述几个渠道脱不了干系,也有可能是直接下载的公开数据集进行转卖。
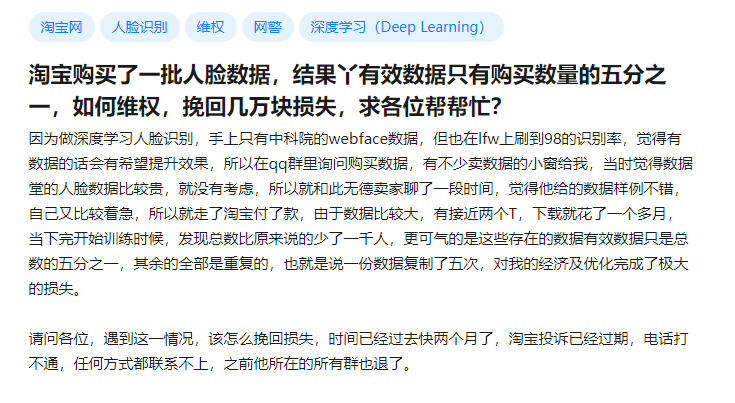
人脸数据被卖了也好,流向人脸数据集也罢,归根结底,后续的应用是完全失控的。
“裸奔”的人脸数据,防不胜防的风险
如果早期我们收集人脸数据还是在志愿者的知情同意下获取,后期就完全摒弃个人隐私,直接通过爬虫程序,美其名曰要遵守共享知识协议,但很多人在上传自己的照片到社交平台、互联网相册的时候,压根不知道这些图片已经被纳入了这个协议下。
就像前阵子掀起轩然大波的ZAO,在密密麻麻的用户协议中,一排不起眼的条款提到“同意授予ZAO及其关联公司以及ZAO用户全球范围内完全免费、不可撤销、永久、可转授权和可再许可的权利”,如果没有后续的风波,你的人脸数据悄然无息间就被“卖”了。
当前,收集人脸的途径非常多,除了政府部门的安保需要,很多商业场景也都要求使用面部识别。比如参加某个大型会议,主办方需要提供个人照片提前录入到人脸识别系统;比如住酒店,需要面部识别确认;再比如一些社交APP,自动识别标记上传图片中的人脸;还有一些披着相册应用外衣,实际是收集人脸信息的软件程序……
之前Facebook因“未经用户同意,非法收集并存储数百万用户的生物识别数据”被集体起诉,在今年9月,压力之下的Facebook选择停止在用户的照片和标签建议中默认使用面部识别功能。

当你把包含自己人脸的照片上传到云端,没有人确保最终这些人脸数据可以被妥善保管。上传到平台,必然涉及到会不会保存到云端,如果在云端,数据最终流向何处呢?带来的风险是什么?
其实从人脸数据集的来源渠道也能了解到上传面部照片到网上的风险是非常高的。
此前有媒体曝光,国内一家人脸识别公司发生大规模数据泄露事件,超过250万人的数据可被获取,其中包括姓名、身份证号码以及照片。
今年年初,美国海关和边境保护局收集的旅客照片和车牌照片让一个外包公司泄露,而流出的数据已经被人挂在暗网上,可以免费下载。
类似新闻层出不穷,所以人脸数据引发的风险也非常高,当隐私信息被出售或者可被公开获取后,人脸可以用于金融领域的诈骗、亦或是在换脸软件下,被用在一些不当的场合下,比如将你的脸成小视频的女主角。除此之外,围绕人脸识别系统的种族歧视和偏见争议,也引发了巨大争议。
人脸保卫战,收集容易监管难
有的时候,技术和应用会处在相悖的一个状态,一方面,算法需要大量的人脸数据去优化,从而带来更准确、安全、高效的识别,避免可能会发生的欺骗性行为,另一方面,在优化算法的过程中又难以保证人脸数据的安全和不滥用,算法应用到场景中又会再次无限制收集更多的人脸数据,最终陷入两难的局面。
研究人脸识别的技术公司非常多,从CV四小龙到谷歌、微软、亚马逊、阿里巴巴这样的科技巨头,它们借助技术提高社会效率的同时,也会掉入舆论的旋涡中。
就在最近,继支付宝要在三年投入30亿推动刷脸支付后,有消息称微信也将拿出100亿补贴刷脸硬件设备的推广,当人脸作为常态的身份认证方式,保卫人脸安全也愈加重要。
但人脸数据收集容易,监管却是难上加难,无论是国外还是国内,在人脸数据安全上都显得忧心忡忡,美国的旧金山和萨默维尔已经通过立法的方式禁止在公共场所使用面部识别技术,其中旧金山是禁止警察和其他政府机构使用面部识别技术。这种一刀切的管理方式,虽然一定程度上规避了风险,但治标不治本。
国内的话,因为人脸识别走进教室以及换脸软件ZAO的病毒式传播,不少人开始注意到人脸数据安全的问题。近日有消息,有关部门将发布人脸识别领域相关金融标准,以明确人脸信息采集、传输、存储、利用等环节的安全管理要求。
其实,谈到如何保护我们的人脸数据,无外乎三个方面。除了个人提高安全意识之外,采集人脸数据的商业公司也需要通过技术手段保护数据的安全,监管部门则从制度层面加快相关法规标准的落地。
悲观的想,技术是双刃剑,虽然我们通过规则约束可以减少一定的风险,但有买卖,就有伤害,只要技术需要,你的人脸数据去哪儿了,被用作什么,可能谁也不知道。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 Facebook
斯坦福大学
旷视
淘宝
病毒
Facebook
斯坦福大学
旷视
淘宝
病毒