
15项领先科技成果发布,阿里、华为、寒武纪、旷视等摘奖,芯片及深度学习依然大热
领先科技成果的发布,是当前科技产业中最前沿、最硬核的产业高速发展的一种印证。
一年一度的“科技界奥斯卡颁奖典礼”在昨晚盛大开幕了。
作为世界互联网大会的“招牌栏目”,2019年15大领先科技成果终于发布。这一次,达摩院、华为、赛灵思、寒武纪、特斯拉、百度、旷视、曙光、360均有成果上榜,产品集中在芯片、深度学习平台、AI训练模型和加速平台、数据库、高性能计算机等领域,均是当前最前沿、最硬核的新兴成果,可谓“星光熠熠”。

当然,这次“盛典”既是对年度技术成果的肯定,也是各家“暗暗较劲”的“舞台”。以下就是各家“较劲”的成果。
华为:自研处理器鲲鹏920
鲲鹏920处理器,是华为在今年年初发布的一款数据中心高性能处理器,由华为自主研发和设计,旨在满足数据中心多样性计算、绿色计算的需求。该处理器兼容ARM架构,采用7nm工艺制造,可以支持32/48/64个内核,也是业界首颗64核的数据中心处理器,主频可达2.6GHz,支持8通道DDR4、PCIe 4.0和100G RoCE网络。

性能方面,华为方面称鲲鹏920的性能较业界主流处理器高出了25%,内存带宽则高出了60%之多。除此之外,这款处理器还支持CPU、桥片、网络和磁盘控制器“4合1”,是业界集成度最高的数据中心处理器之一。
从2004年开始,华为便开始了嵌入式处理芯片的研发,超2万名工程师历时15年,让华为拥有了以“鲲鹏+昇腾”为核心的基础芯片族。
清华大学:AI异构融合芯片“天机芯”
“天机芯”是清华大学类脑计算研究中心研发的一款新型AI芯片,今年8月,第三代“天机芯”曾登上《Nature》封面。

通过资源复用,“天机芯”可以做到只需3%的额外面积开销,即可同时运行计算机科学和神经科学导向的绝大多数神经网络模型(同时支持机器学习算法和现有类脑计算算法),且支持异构网络的混合建模,形成时空域协调调度,在发挥各自优势的同时,做到降低能耗、提高速度和保持高准确度。
在清华大学的实验中,他们用一块芯片构造一个类脑自行车,该自行车可以像人一样探测感知、过障避障、自动控制,是类脑通用智能的一个雏形。
特斯拉:完全自动驾驶芯片(FSD)
FSD由特斯拉自主研发,是一款完全自动驾驶芯片。今年4月,特斯拉首次发布这款芯片时介绍称,“FSD是由两套完全一样的独立系统组成,每个系统的处理器都拥有12个A72内核、1个神经网络处理器和1个GPU。”

值得一提的是,FSD神经网络处理能力非常强悍,可以同时处理汽车上8个摄像头同时工作的数据,即在每秒图像输入2300帧的情况下,可以每秒实时处理25亿像素的数据,是业界相关硬件平均能力的21倍。
而除了双神经网络加速器,特斯拉还为FSD增加了冗余电源、冗余计算和独立安全芯片设计,可以保证高速行车场景下的自动驾驶功能运行,以及及时监控黑客攻击自动驾驶汽车的可能性。
寒武纪:云端AI芯片思元270
今年6月,寒武纪发布了第二代云端AI芯片思元270,这也是该公司在处理器架构领域的创新技术突破。

寒武纪方面介绍称,思元270中集成了120亿个晶体管,处理稠密机器学习模型的理论峰值性能较上一代提升了4倍,达到了128TOPS(INT8),且兼容INT4和INT16运算。
除此之外,该芯片采用的是寒武纪自研的MLUv02指令集,可支持高度多样化的AI应用,如视觉、语音、自然语言处理、传统机器学习等。其中,思元270在视觉应用上,还集成了充裕的视频和图像编解码硬件单元。
赛灵思:Versal自适应计算加速平台
赛灵思的Versal ACAP是业界首款自适应计算加速平台,也是一个异构计算平台,集多样性和通用性为一体,可面向所有应用及开发者的平台。

赛灵思介绍称,Versal整合了三种类型的可编程处理器,包括标量引擎双Arm Cortex-A72和Cortex-R5处理器、自适应引擎PL、智能引擎即AI引擎和DSP引擎。
其中,AI引擎为赛灵思独创的一种新型硬件模块,可用于定点和浮点运算的向量处理器、标量处理器、专用程序和数据存储器、专用AXI 数据移动通道、DMA和锁止,且针对计算和DSP进行了优化,支持高吞吐量和高性能计算。
Versal还可以在硬件和软件级别进行更改,以适应从边缘到云的各种应用需求。
微软:统一预训练语言模型
微软在今年发布了他们最新的预训练语言模型——统一预训练语言模型,即统一自然语言预训练模型与机器阅读理解。据官方介绍,这一模型拥有两大技术创新:
提出了统一的预训练框架;
部分自回归预训练范式。
早在2016年,微软的AI就曾在152层残差图像识别中获得了高达96%的准确度,相当于一名斯坦福研究生的识别水准。前年,微软又在Switchboard数据集测试中将AI的误差率降到5.1%,达专业速记员水准。
2018年,微软在SQuAD(斯坦福文本理解挑战赛)上取得了超越人类的分数,在英汉、汉英新闻的机器翻译测试中的结果也与人类水平持平,可见其智能度正在快速提升。
百度:飞桨
飞桨,即PaddlePaddle,是百度自研的深度学习平台,集深度学习核心框架、模型库、工具组件和服务平台于一体,是一个开源开放的产业级深度学习平台。
飞桨拥有五大优势:
同时支持动态图和静态图,兼顾灵活性和高性能;
实际业务方面,提供应用效果领先的官方模型;
产业实践方面,输出业界领先的超大规模并行深度学习平台能力;
速度体验方面,推理引擎一体化设计可实现训练到多端推理的无缝对接;
提供系统化技术服务与支持。
阿里:POLARDB
POLARDB是阿里云自主研发的,基于存储计算分离与分布式共享存储架构的新一代分布式云原生数据库,既拥有分布式设计的低成本优势,又具有集中式的易用性,即实现了计算节点及存储节点的分离。
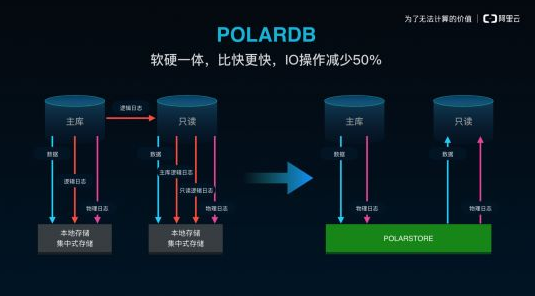
除此之外,POLARDB还具有智能化管控、全链路加密、数据热迁移等功能,是阿里“双11”优秀的后台支撑之一。目前,该数据库已经被广泛用于政务、金融、保险、新零售、交通、教育和互联网等多个领域。
旷视:人工智能计算平台Brain++
Brain++是一套端到端的AI算法平台,具备大规模算法研发能力,目标是让研发人员获得从数据到算法产业化的一揽子技术能力,以推动AI快速落地应用。
从2014年开始,旷视就投入到Brain++的相关研发工作,目前,该平台已具备三大核心功能:
针对视觉任务定制化优化,适合大规模图像及视频训练及完成复杂的视觉任务;
配备AutoML技术,可以让算法来训练算法,即让AI创造AI;
拥有多任务及多用户调度能力,智能调度平台硬件基础设施的计算能力,可支持数百名研究人员,同时在数万个GPU芯片上执行训练任务。
据旷视方面介绍,未来Brain++将实现开源,用于建立完善的AI产业生态,
曙光:硅立方浸没液冷计算机
突破传统计算机冷却方式,曙光的硅立方浸没液冷计算机采用的是浸没相变液冷,将服务器芯片、主板等部件都浸没在液体中,计算机一旦运行,液体便会带走热量,PUE(评价数据中心能源效率的指标)低至1.04,较业内平均值提升了30%。通俗来说,就是在“泡冷水澡”。

反应到实际应用上,如果我们用的全是硅立方浸没液冷计算机,那么每年节省的电量将达400亿度。
除此之外,曙光方面还介绍称,硅立方浸没液冷计算机攻克的是能耗瓶颈,可以支持AI、大数据、云计算等高密度算力应用。
中国电信:IPv6超大规模部署实践与技术创新
作为新一代的IP协议,IPv6具有更大的地址空间、更小的路由表、更高的安全性和自动化,且允许扩充。而中国电信设计的新型IPv6网络架构,可以支持多过渡场景和“模块化”升级,已经实现了对用户透明的IT支撑技术,可灵活开通、激活和管理IPv6业务。
除此之外,中国电信提出的映射表溯源方案,处理效率较传统方式提高了数百倍。目前,它已经建成了一个大规模、全业务形态的IPv6网络,城域网、移动网、骨干网、IDC等都已实现了IPv6商用部署,是一个包括端管、云用在内的全新互联网体系。
360:“全视之眼”0day漏洞雷达系统
应对网络攻击,“看不见”的攻击才是最可怕的,如不可预知、极难防御的0day漏洞攻击。
0day漏洞雷达系统就是为捕获0day漏洞攻击而生的。据360方面介绍,该系综合利用冰刃安全虚拟机技术(ILSVM)、智能0day漏洞捕获等自研技术,在攻击的三个阶段均布置了多种全球独创的新型探测器,建立多维沙箱,依托360安全大脑的大数据和智能决策响应能力,及时有效捕获攻击。
目前,“全视之眼”每天能感知到的异常行为已超5亿次。
SAP:智慧企业解决方案
SAP的智慧企业解决方案是一个将AI、生产制造与经营管理结合的商业化平台,实现了端到端的全云应用覆盖。
测算结果显示,该方案可减少60%的人工任务量。
商飞:民用大飞机
大飞机被业界誉为“工业皇冠”,C919大型客机全称COMAC C919,是中国首款按照最新国际适航标准,具有自主知识产权的干线民用飞机,最大载客量达190座。

腾讯:科技向善
“科技向善”是腾讯提出的一种理念,即将云计算、大数据、人工智能等融合到各大产业中,用科技助力现代智慧型城市综合治理实践。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 双11
教育
硬件
科学
移动
双11
教育
硬件
科学
移动