
DeepMind的AI再次打败人类玩家,“攻下”57款雅达利游戏
Agent57为我们构建更加强大的AI决策模型奠定了基础。
AI打游戏会比普通人优秀?DeepMind给了肯定的答案。近日,DeepMind宣布它们的智能体Agent57首次在所有57款雅达利游戏上超越人类玩家。

近年来,DeepMind一直在研究提高智能体在游戏环境下的智能性,通常情况下,智能体在游戏中能够应对的环境越复杂,它在真实环境中的适应能力也会越强。
此次Agent57挑战的街机学习环境(Arcade Learning Environment,ALE)包括57款游戏,为智能体的强化学习提供了复杂的挑战。
而之所以会选择雅达利游戏作为训练的数据集,DeepMind表示雅达利游戏足够多样化,可以评估智能体的泛化性能,其次它可以模拟在真实环境中可能遇到的情况,并且雅达利游戏是由独立的组织构建,可以避免实验偏见。
据悉,Agent57在多台计算机上并行执行,并启用强化学习算法(Reinforcement learning,RL)驱动智能体采取行动,使得奖励的效果最大化。此前,强化学习在游戏领域就取得不少进展,比如OpenAI的OpenAI Five和DeepMind的AlphaStar RL智能体分别打败了99.4%的Dota 2玩家和99.8%的星际2玩家。
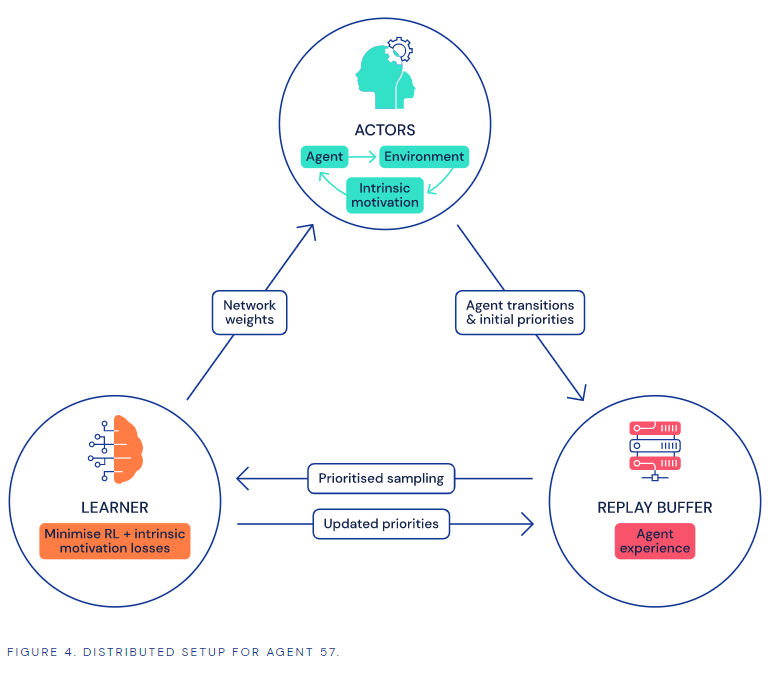
图 | Agent57的框架
雅达利游戏中的Montezuma、Revenge和Pitfall都很难,AI必须先尝试多种不同的策略,才能找到可行的方法。而在Solaris和Skiing游戏中,需要一段时间才能显示决策结果,这意味着AI必须在相当长的时间内收集尽可能多的信息。
Agent57通过让不同的计算机研究游戏的各个方面来克服了这些难题,然后将收集到的信息反馈给一个控制器,由控制器对所有这些因素进行分析以制定出最佳策略。
DeepMind将Agent57与当前最先进的算法MuZero、R2D2和NGU做了比较,Agent57显示出了更高的平均性能(100)。
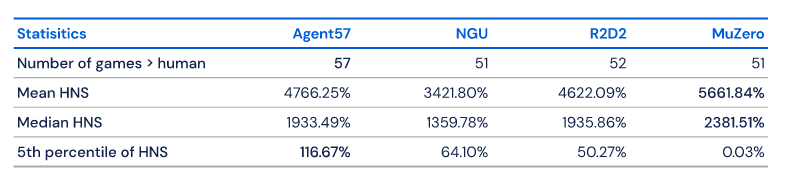
研究团队表示,“这并不意味着雅达利游戏研究的结束,我们不仅要关注数据效率,也需要关注总体表现,未来的主要改进可能会是Agent57在探索、规划和信度分配上。”比如减少AI运行的算力,在集合中的一些较简单的游戏中变得更好。
Agent57在雅达利游戏中取得超越人类玩家的成绩,为我们构建更加强大的AI决策模型奠定了基础:AI不仅可以自动完成重复性的任务,也可以自动推理环境。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 360
OpenAI
游戏
算法
计算机
360
OpenAI
游戏
算法
计算机