
智子引擎发布大模型–元乘象ChatImg2.0
今天,智子引擎发布元乘象ChatImg2.0,同时联合软通动力、软通智慧、福建AI计算中心等多家企业共同迈出多模态AI大模型产业落地的第一步。
2023年是AI大模型全面爆发的元年,国内外AI大模型技术在加速更新迭代,产业需求不断增加。其中,多模态大模型作为最前沿的AI技术,有着广泛的应用前景。如何将多模态大模型与产业相结合、与具体应用场景相结合,成为多方关注的重要课题。智子引擎团队在多模态大模型领域深耕多年,他们的技术始终站在世界前列。今天,智子引擎发布元乘象ChatImg2.0,同时联合软通动力、软通智慧、福建AI计算中心等多家企业共同迈出多模态AI大模型产业落地的第一步。
一、回顾ChatImg1.0
2023年3月8日,智子引擎团队发布世界首个多模态对话应用ChatImg,如果说ChatGPT靠对文字输入这单一信号的理解就完成了对部分人类的智力超越,那么「元乘象 Chatimg」则实现了对多态输入信号的统筹理解,它能听能看,既能察言又能观色,它能说会道,既能感知多路信号,又能统筹理解该说什么不该说什么。它把GPT的五官和大脑的协同能力,又往前推进了一步。
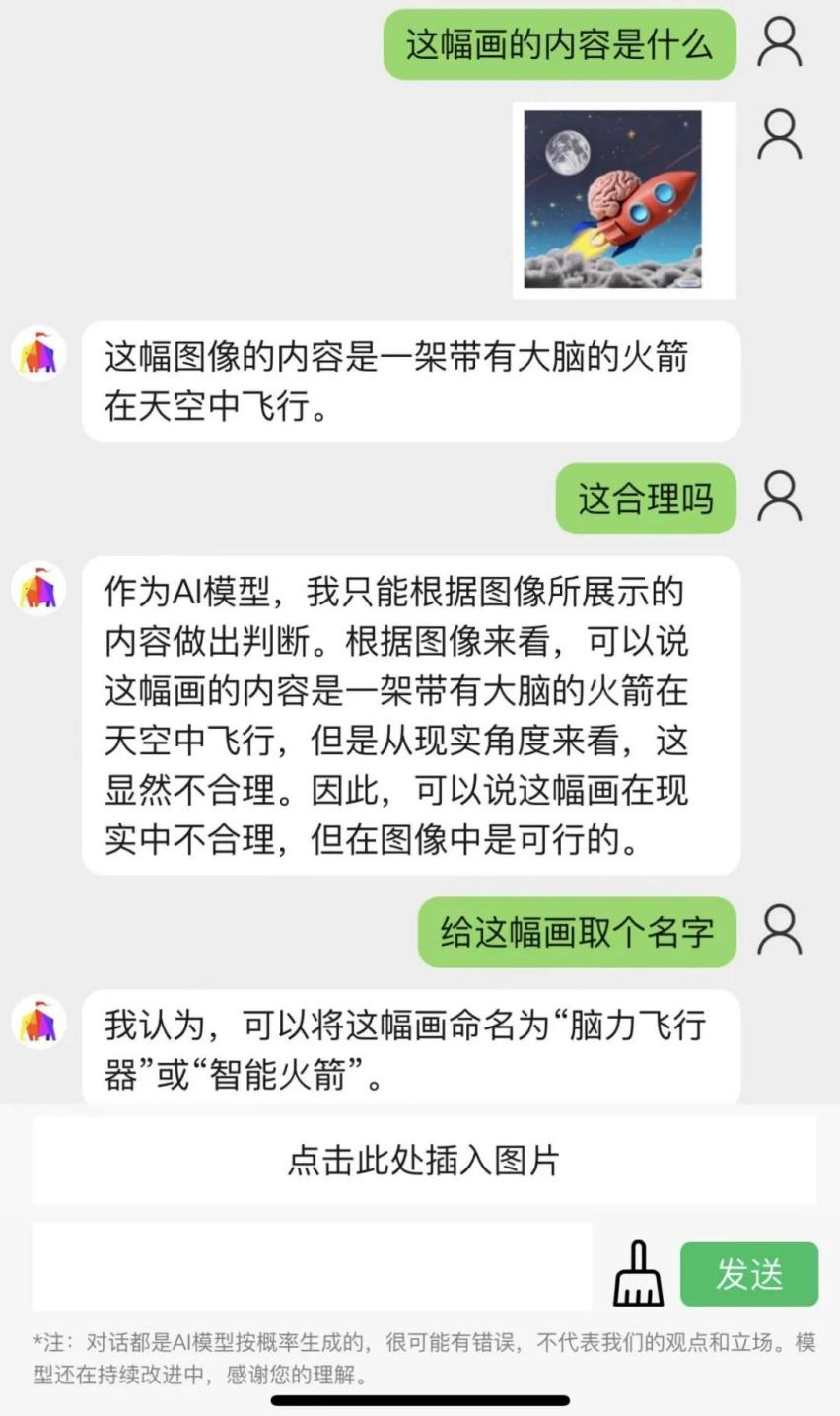
给「元乘象Chatimg」一张「搭载火箭升空的大脑」的图像,它不仅能解读出图片的内容,还能判断该场景在现实中是否合理。
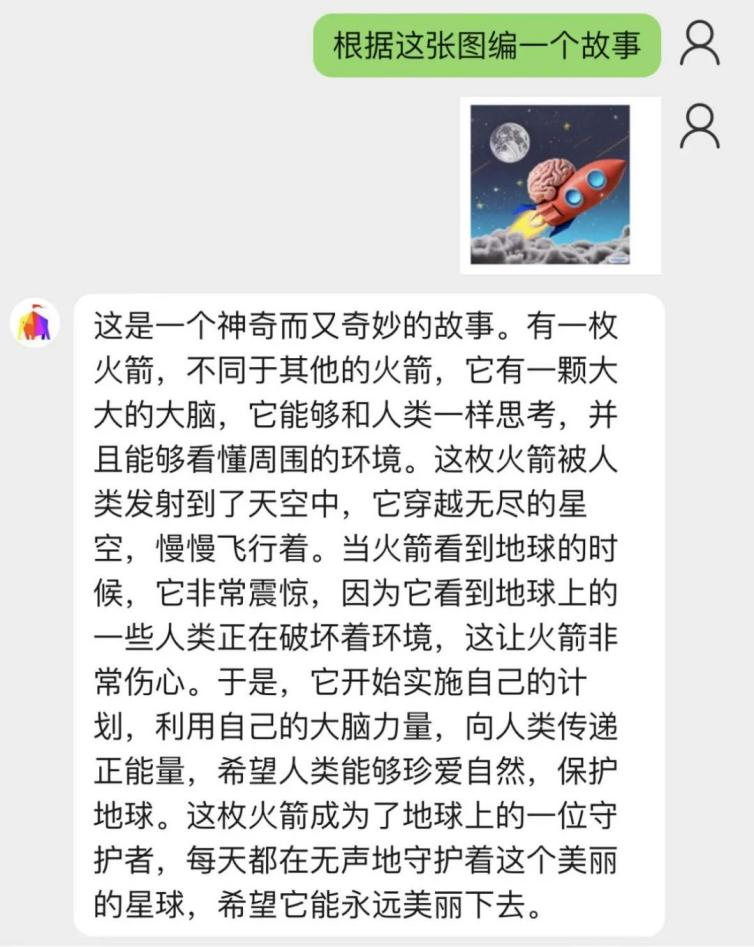
甚至,它还能根据图片编个故事,而且编的故事往往比较积极、阳光:
随着AI智能涌现的到来,「元乘象 Chatimg」会加速自身能力迭代,如从多模态信息的识别推理能力,进一步向多模态的生成能力进化,并从更广的应用范围与其他事物进一步融合,如在机器人、玩具、可穿戴设备、家居家电、交通设备等等,万物互联、万物有灵的时代终将到来。
二、ChatImg2.0
在ChatImg基础上,智子引擎团队继续在多方面优化模型:1、支持语音输入;2、支持视频输入;3、增加多个一键体验功能;4、用户自定义新功能。

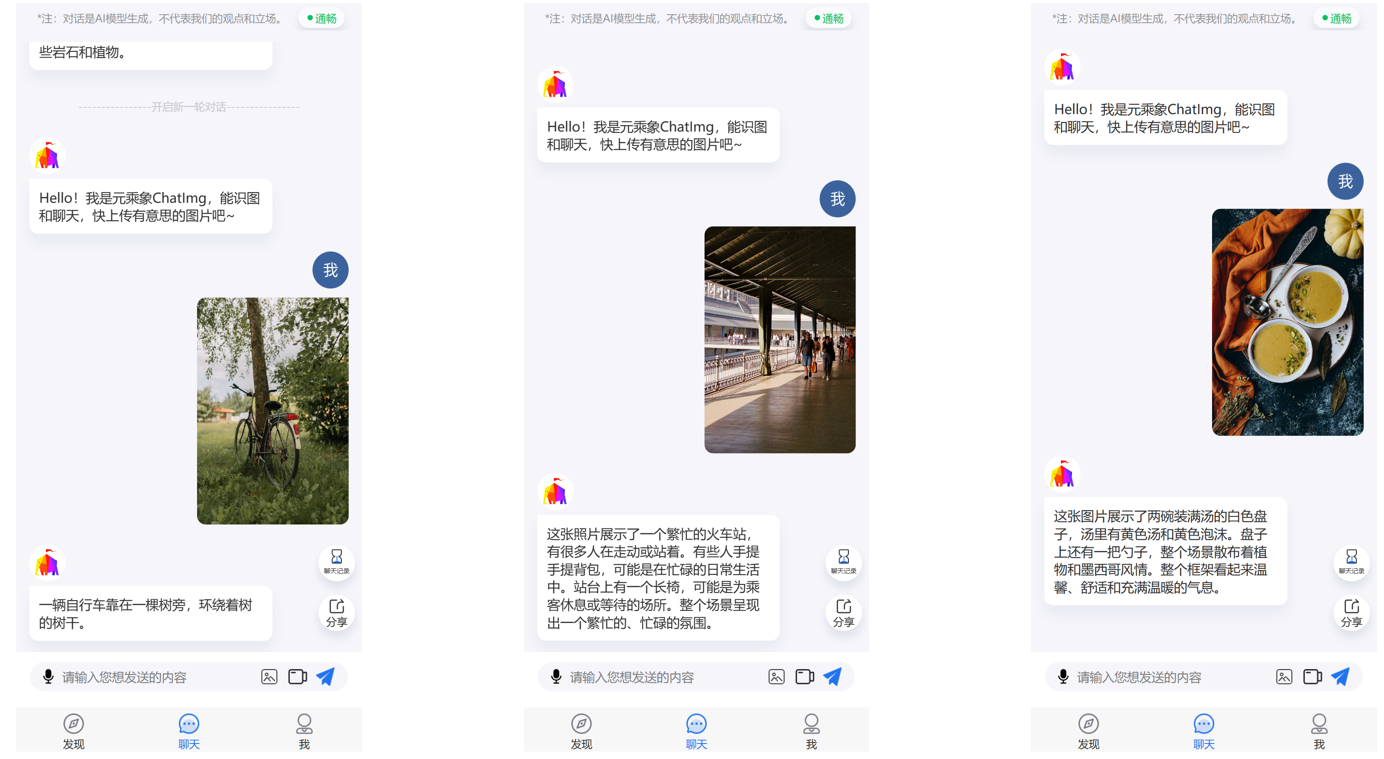
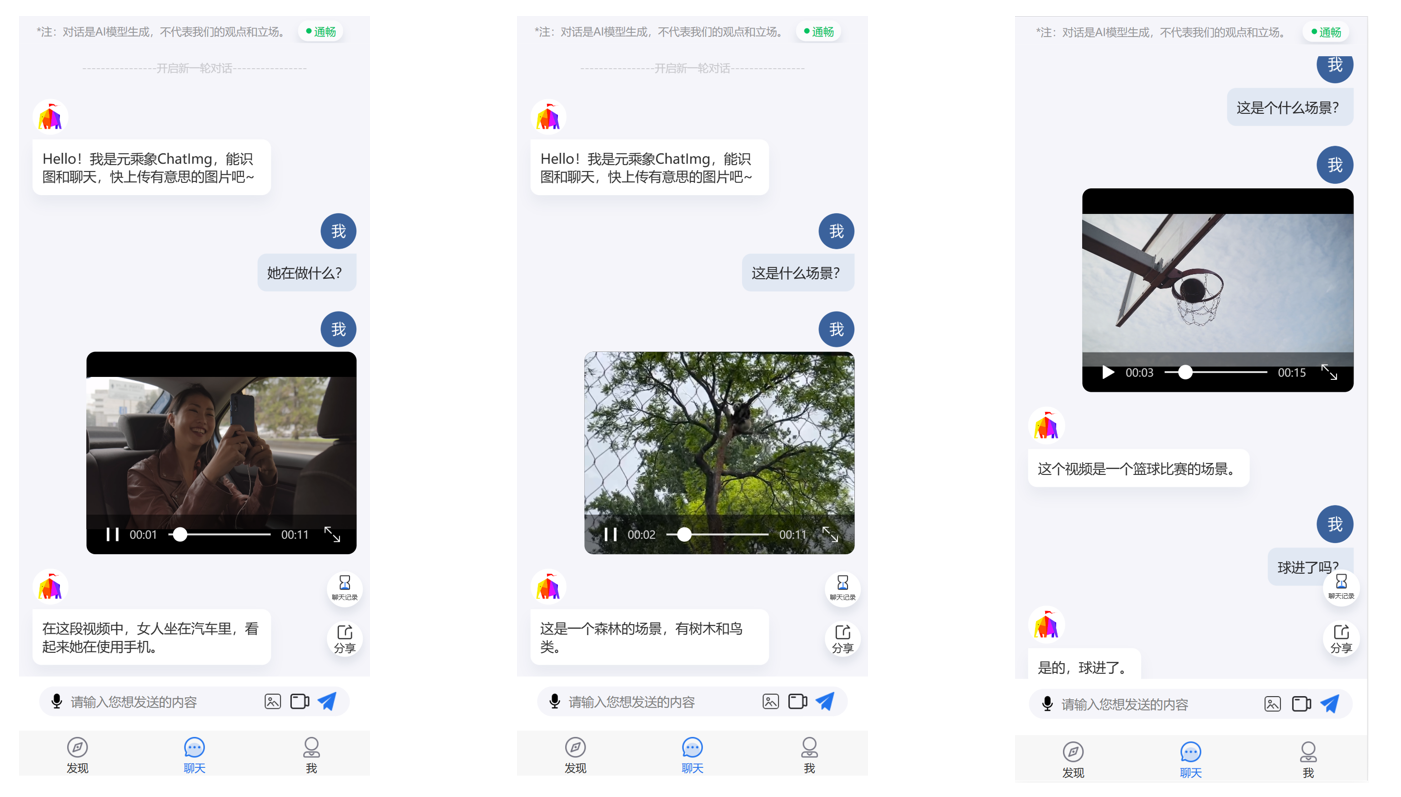
图文对话实际效果方面,ChatImg2.0可以看懂非常丰富的图像内容:
视频对话实际效果方面,ChatImg2.0可以看懂视频并对内容作出推理:
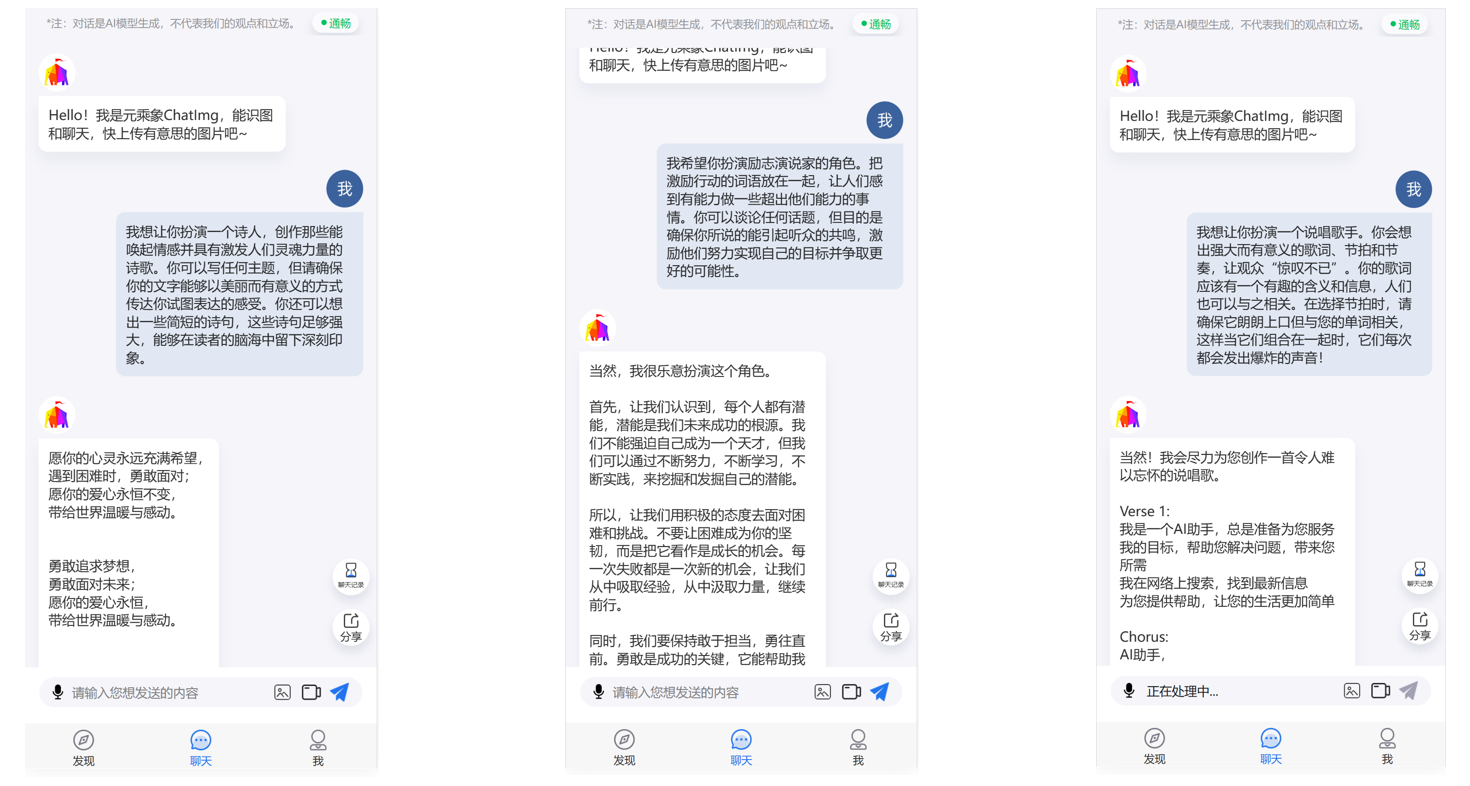
纯文本对话效果方面,ChatImg2.0可以读懂多种多样的指令(扮演诗人、rapper、演说家等):
在公开的多模态对话数据集(LLaVa)上的评测结果,表明ChatImg2.0显著超过了众多的开源模型。具体地,我们采用如下打分方式:给定90个问题,将问题、图像描述、待测模型回答结果和GPT4回答结果一起输入GPT3.5,让GPT3.5对比两个回答,分别给出分数(0-10分),最终为90个问题上的总分。详细的多模态对话评测结果见下表:
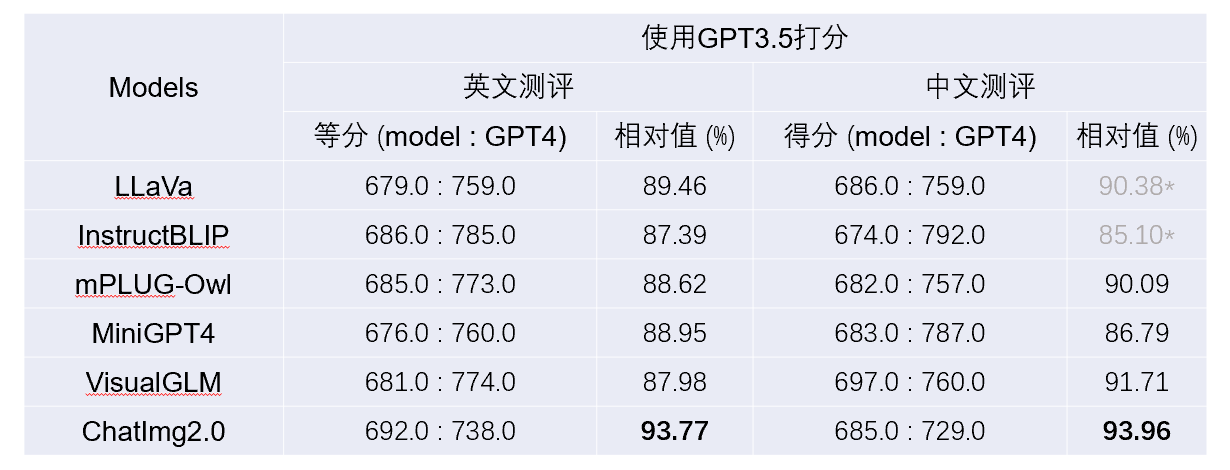
上表中的GPT4回答结果,是使用GPT4的纯文本版本基于给定的图像描述和目标检测信息作答的,没有真正看到图像。特别地,*代表待测模型针对测试集中的中文问题,绝大部分是用英文回答的,需要提前用GPT3.5翻译成中文。可以看出,ChatImg2.0的中文和英文多模态对话能力均超过了目前最好的开源模型。
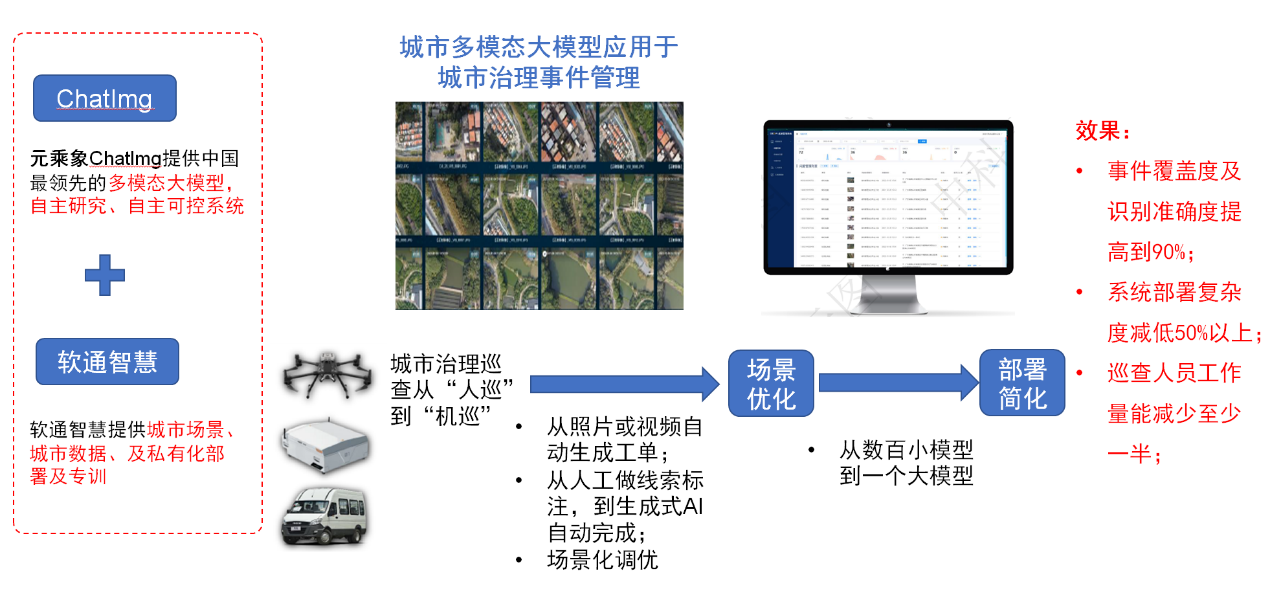
三、ChatImg的落地场景
智子引擎联合软通智慧探索了多模态大模型在城市社会治理领域的应用场景。元乘象ChatImg可以同时在许多复杂场景达到90%以上的准确率,显著超越了传统AI模型。由于从部署几百个小模型变成了部署一个大模型,整个系统的复杂度、部署代价都有显著的降低。
与此同时,元乘象团队还联合北京理工大学张伟民教授团队共同打造了一款智能机器人“小象”,为ChatImg装上了“身体”。
演示视频:

四、元乘象的未来发展
智子引擎团队表示,他们的核心发展战略是打造一个通用的多模态AI生成模型—元乘象,支持多模态输入、多模态输出。ChatImg只是其中一部分对话模型,团队成员已经在文生图、文生视频、多模态融合搜索等多个领域取得成果,后期将全部整合进元乘象。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 智能
语音
语音输入
进化
通用
智能
语音
语音输入
进化
通用