
三角兽与华为麒麟970联合演示芯片级语义处理方案
三角兽与麒麟970联合演示本地快速处理智能语义意图及信息提取、智能表情生成、智能自动回复等功能,强化手机终端精确语义认知的能力,
当前,人工智能已经是最热门的技术。但纵观产业界,大多人工智能的技术和能力都是在云端部署,很少有在端侧部署的。今年9月,华为发布的麒麟970和苹果发布的A11这两款业界仅有的人工智能手机芯片,彻底改变了产业格局。其中,华为发布的麒麟970是业界首款人工智能手机芯片,是在端侧人工智能领域的一次突破性探索,开创了人工智能手机应用行业先河。
作为全球领先的ICT厂商,华为此次能够在全球率先推出人工智能手机芯片麒麟970 并不令人意外。相较前作960,除了CPU能效提升20%,GPU性能提升20%、能效提升50%之外,还创新设计了HiAI移动计算架构,首次集成NPU(Neural Network Processing Unit)专用硬件处理单元,其AI性能密度大幅优于CPU和GPU。相较于四个Cortex-A73核心,在处理同样的AI应用任务时,新的异构计算架构拥有大约25倍性能和50倍能效优势,这意味着麒麟970芯片可以用更少的能耗更快地完成AI计算任务。作为对深度学习、人工智能的前瞻性探索,华为这次用芯片级的方案,对硬件做到了“底层武装”。

三角兽与麒麟970联合演示本地快速处理智能语义意图及信息提取、智能表情生成、智能自动回复等功能,强化手机终端精确语义认知的能力,打造极致手机操作和交互体验。在这些功能的基础上,可为手机拓展出丰富多样的解决方案,让手机更懂用户,提供更好的交互体验。

那么,这些功能具体是什么,又该如何应用呢?让我们详细研究一下:
1.智能语义意图及信息提取
智能分析文本隐含的语义意图并提取关键信息,对应到相关的功能和服务,以此优化用户文本编辑的效率,减少操作路径。
在我们日常使用手机的过程中,我们经常遇到以下场景:
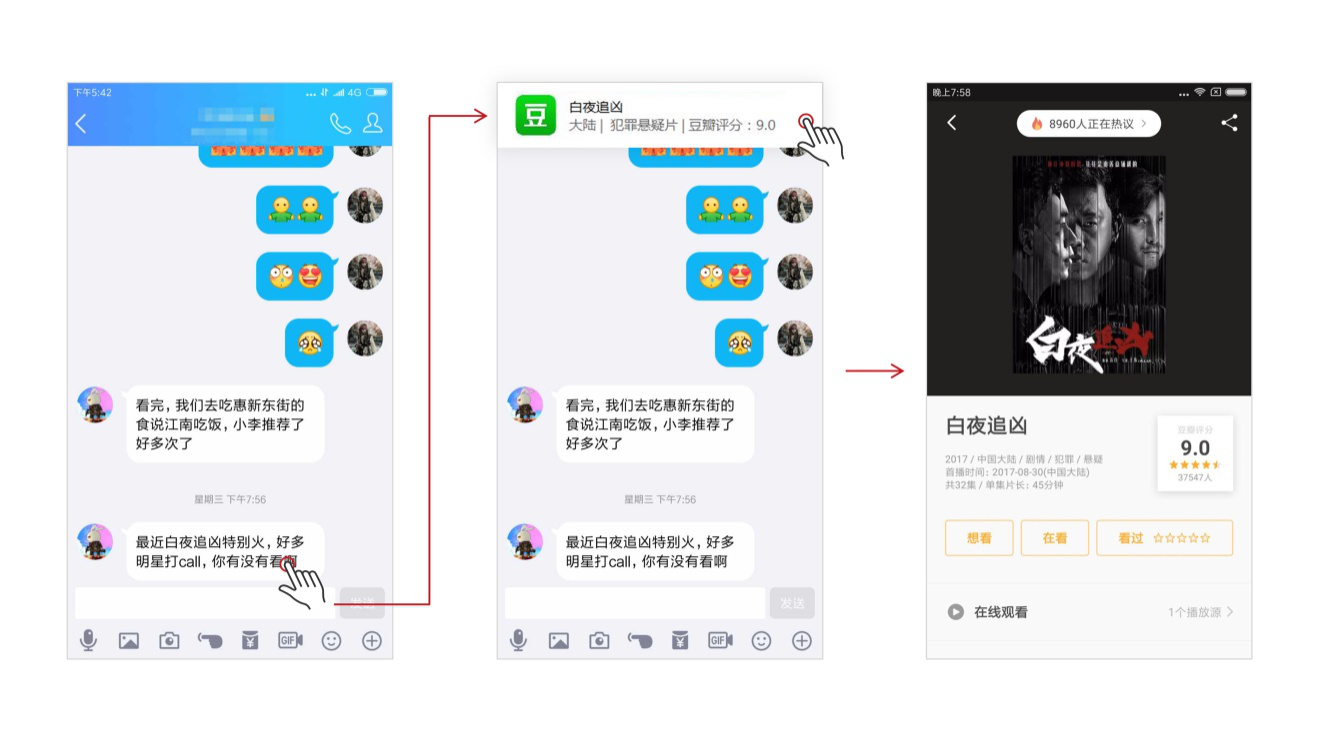
朋友推荐了一个不错的餐厅,希望得知它的价格、环境或导航去它的位置;
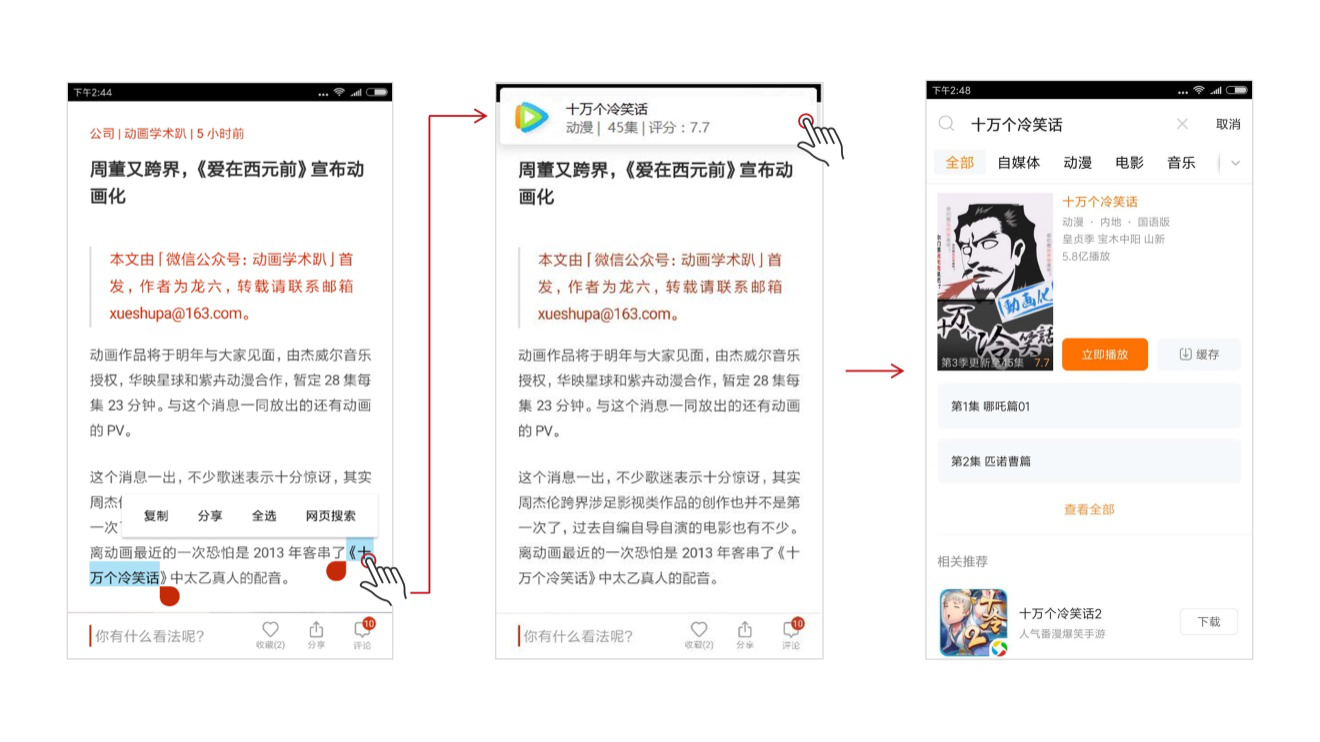
看到感兴趣的歌手的新闻,希望了解TA的更多新闻或收听TA热门的歌曲;
一篇文章中提到的电影,想买一张它的电影票去附近影院观看。
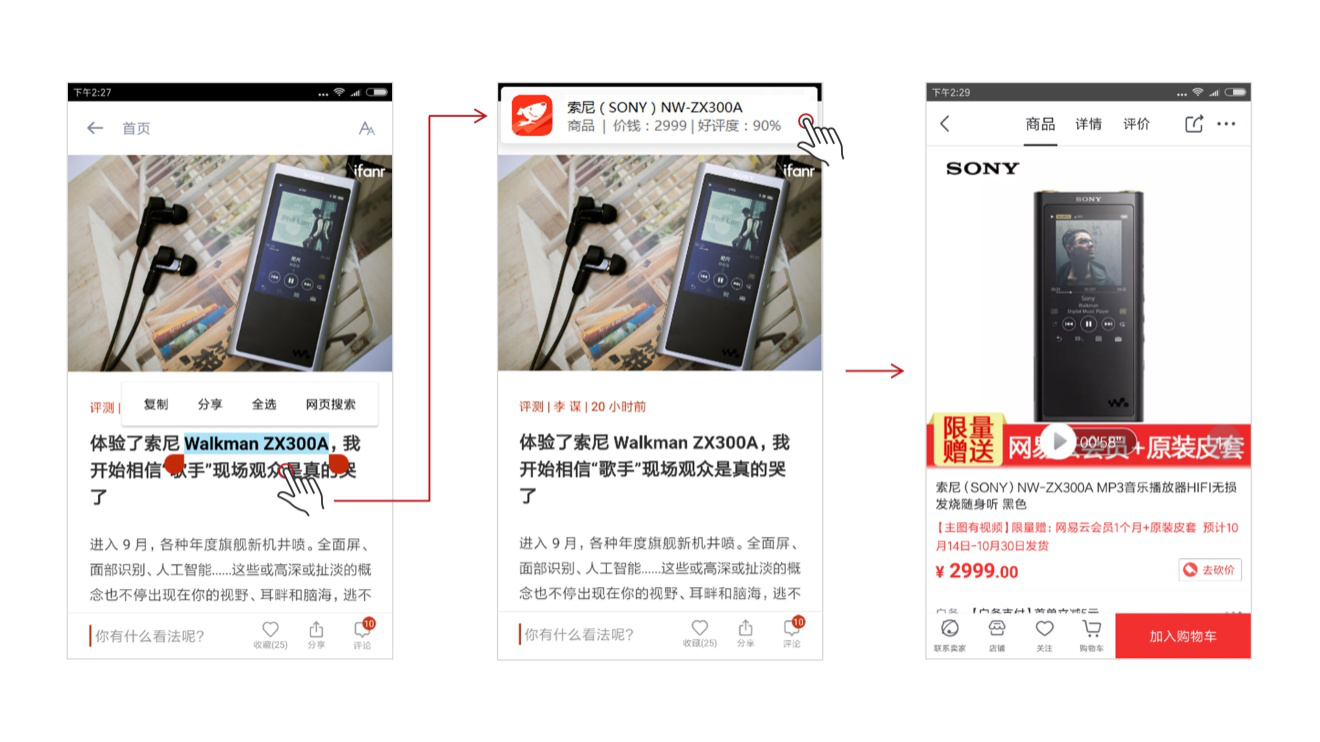
一个感觉不错的商品,想了解商品详情或价格;
在目前手机系统中,进行这些操作都比较繁琐,以微信聊天内容的地址查询举例:
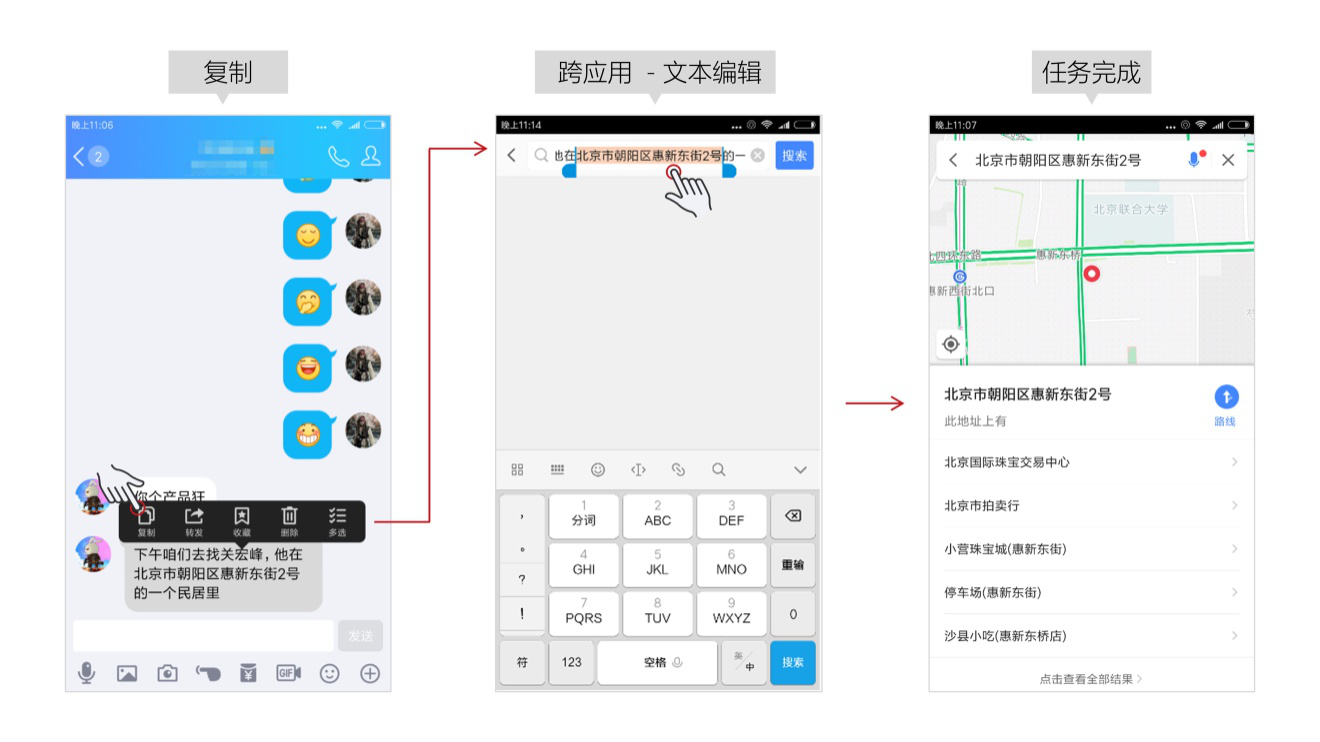
我们需要在复制整段文本后,找到地图应用,然后用“胡萝卜”似的手指对着一群细小的文字不断触碰,精确选择到“北京市朝阳区惠新东街2号”,再进行搜索,才能查询到所需内容。
经过三角兽智能语义理解能力的装备后,这个繁琐的步骤则可以一步到位了,不用找应用,不用为难我们“胡萝卜”似的手指,你只需点击再点击就可以了!
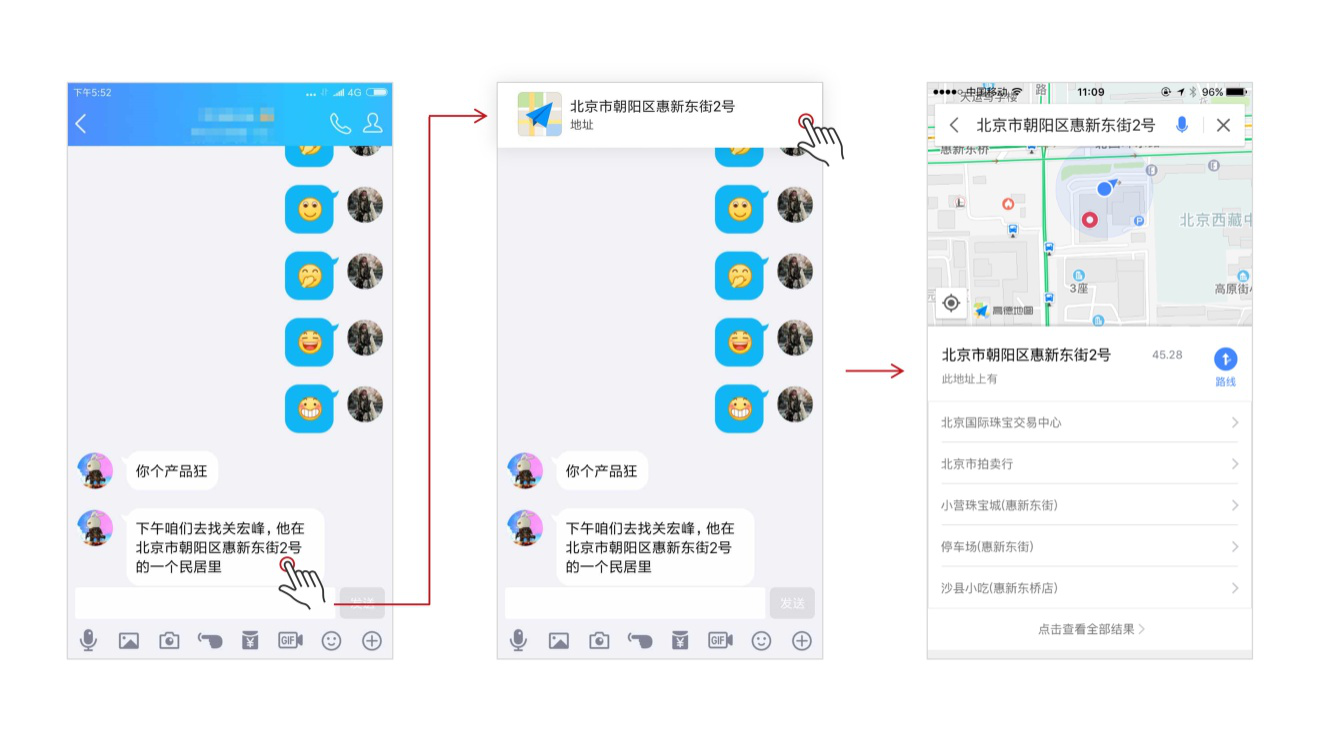
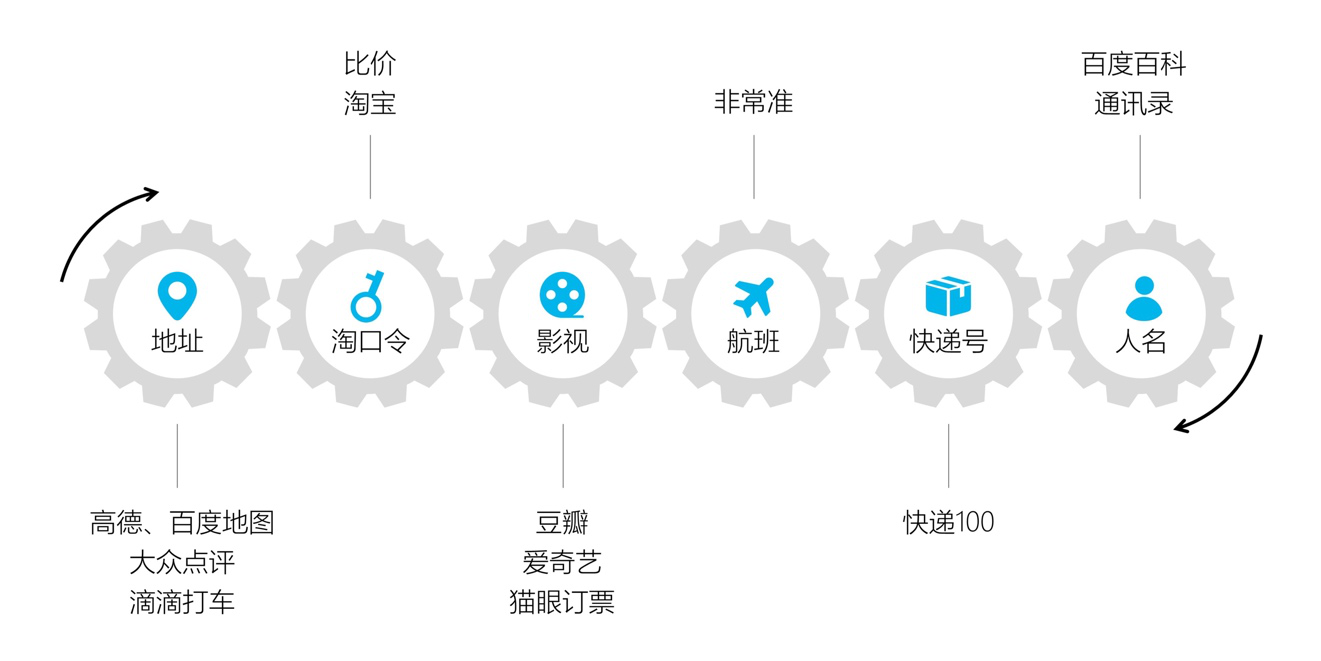
于是,在手机在收到大段信息之后,不管是地址还是吃喝玩乐等信息,都可以同样的一键识别,秒懂你的需求。下面,我们来看几个平时经常出现的具体应用场景:
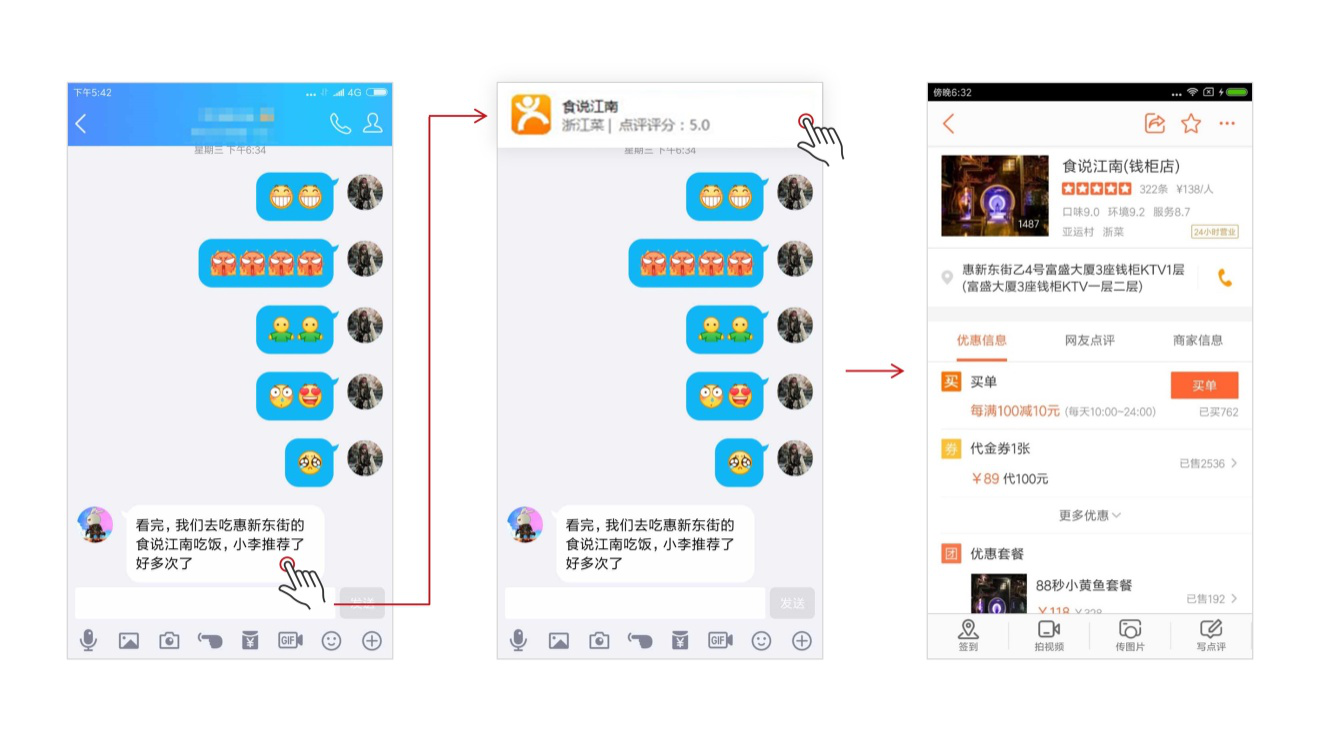
跟朋友聊天、提到了某个餐厅时,选择这段文本,系统就可以识别提取出该餐厅名称,并结合大众点评等app获取它的详细资料,一键直接得知其价格、地址、环境等信息,是不是非常方便?
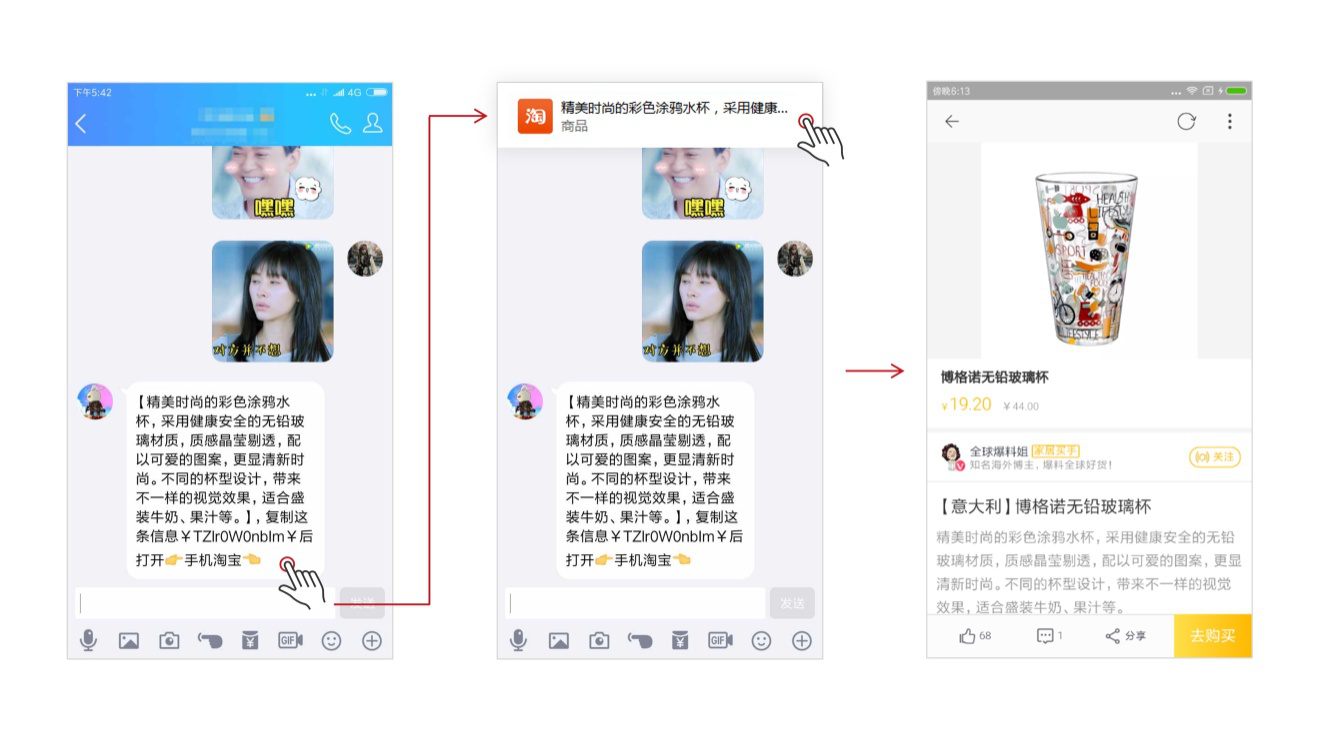
既然这种语义认知能力可以轻轻松松智能识别提取出商店、地址等种种信息,那么商品、视频名称等等关键词自然也不在话下了。在相关app的支持下,用户同样可以一键获取购物链接、视频信息等,轻松实现后续动作。
技术原理:
通过数百万级的各种场景下语料(如新闻、百度百科、百度知道、聊天、论坛、短信等),训练而成Bi-LSTM模型的Seq2Seq模型。
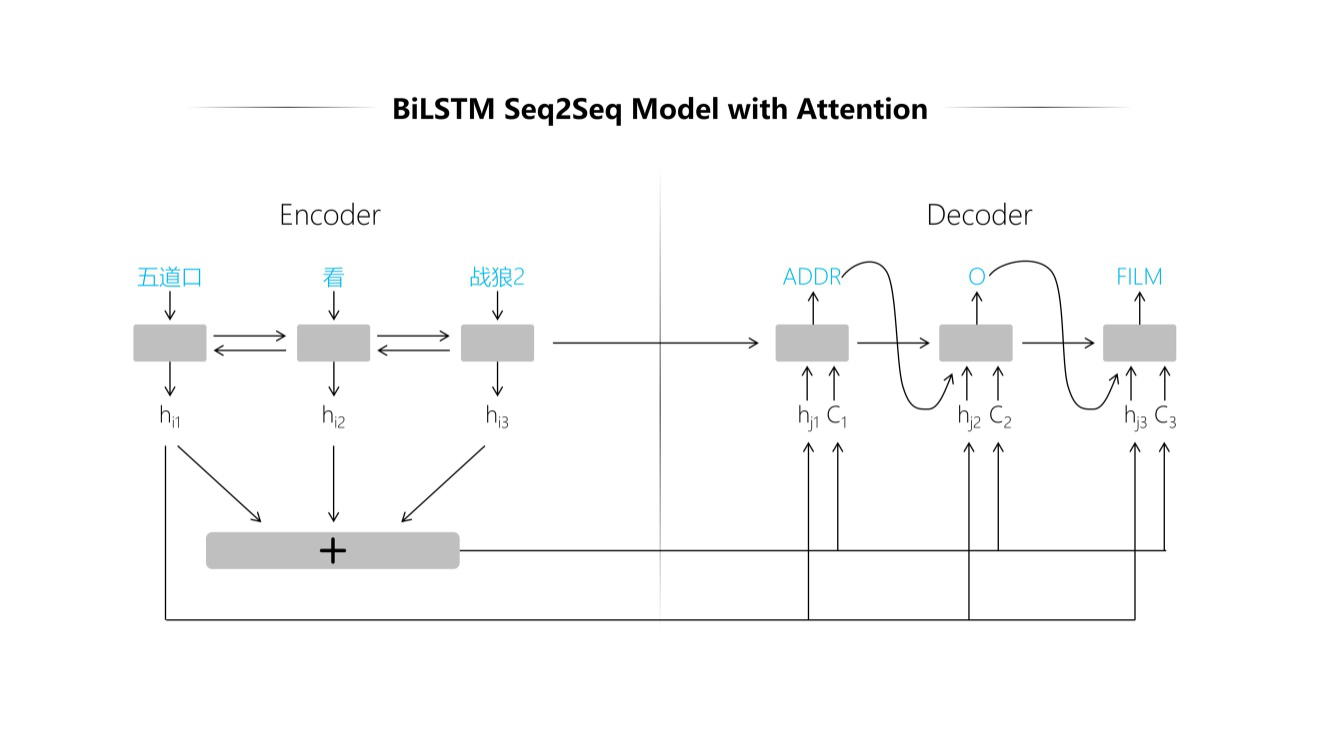
基于Seq2Seq的方法,将命名实体识别抽象为一个序列标注的过程,具体分为Encoder和Decoder两个阶段:
在Encoder阶段,词的序列分别按照句子行文的次序正向和反向通过LSTM的Cell
在每个词的位置,生成截止到当前位置句子的正向和反向语义表示 和 (其中, 表示位置的语义表示,表示正向,表示反向)
在Decoder阶段,按照词序列的顺序,生成每个词对应的命名实体识别的结果(如果不是一个命名实体,则输出Other)
解码阶段,会综合当前位置的隐层语义 ( 表示位置,以下同理),上一个命名实体输出 ,以及基于Attention Mechanism的Context Embedding的三个语义变量,共同构成Decoder LSTM Cell的输入
具体到Context Embedding向量 的计算过程:
根据与encoder阶段的 系列,系列计算Attention的权重
,系列与权重 进行加权求和,得到用于生成位置 的命名实体所需要的上下文语义变量
在Decoder输出隐层语义 之后,再通过Softmax层,将隐层变量空间,映射到命名实体分类体系空间,得到每种命名实体的概率,再选出概率最大的命名实体进行最终输出
这段是不是说的太高深,很难懂?没关系,咱们来个简单的解释:Encoder可以理解为把人类的自然语言翻译为机器语言,Decoder可以理解为机器用自己的语言对人类的自然语言进行解释,识别出每个词语的意义。比如对于“那家渝乡小馆的辣子鸡真好吃”这句话,在Decoder阶段,对于“渝乡小馆”这一实体,计算机对其上文(前序词语)和下文(后序词语)进行理解后,并经过模型的概率计算,得出结果为“渝乡小馆”最大概率是一家餐厅。上文例子中的“五道口看战狼2”中,同样的道理可以将“五道口”识别为地址,“战狼2”识别为电影。
目前,整个模型支持20多种命名实体的识别,可应用于各类不同app与场景中。
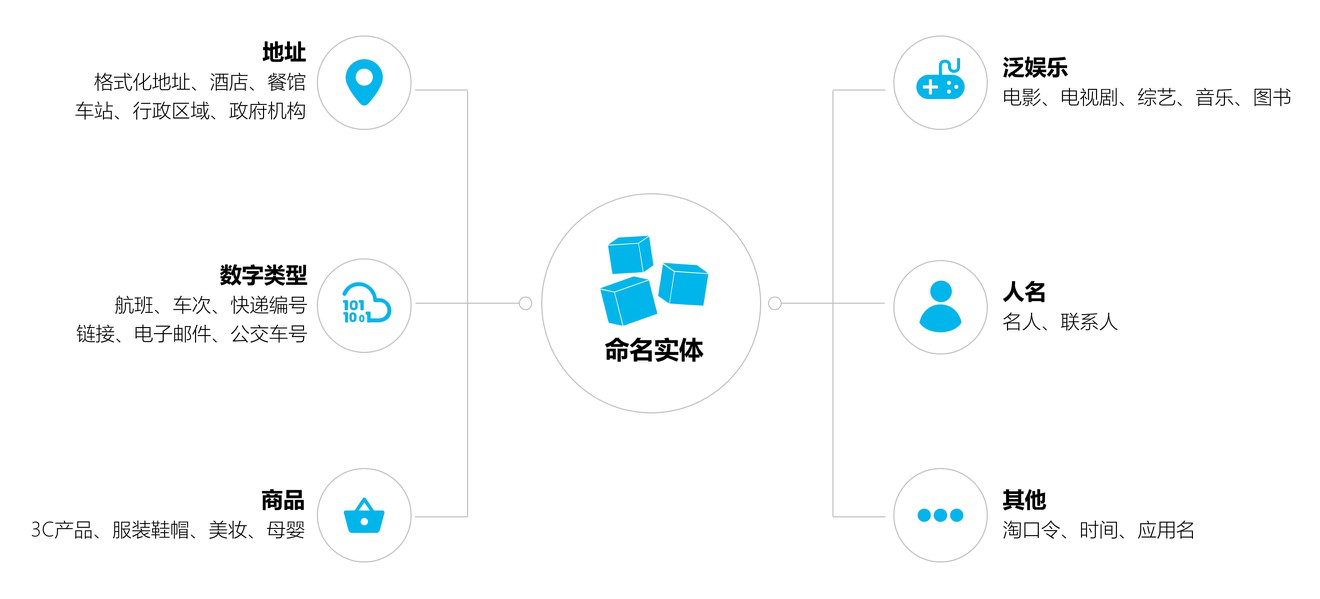
2.智能表情生成
智能分析文本隐含情绪意图,辅助用户选择最合适的表情。
聊天机器人并不罕见,但是一个能准确了解你的心思,还能帮你回复表情表示复杂情绪的机器人,是不是就比较稀有了?装备了智能表情生成功能之后,通过模型,聊天机器人可自行计算判断对话中体现的情绪意图,并在回复时列出概率最高的表情作为备选项,进行便捷回复。
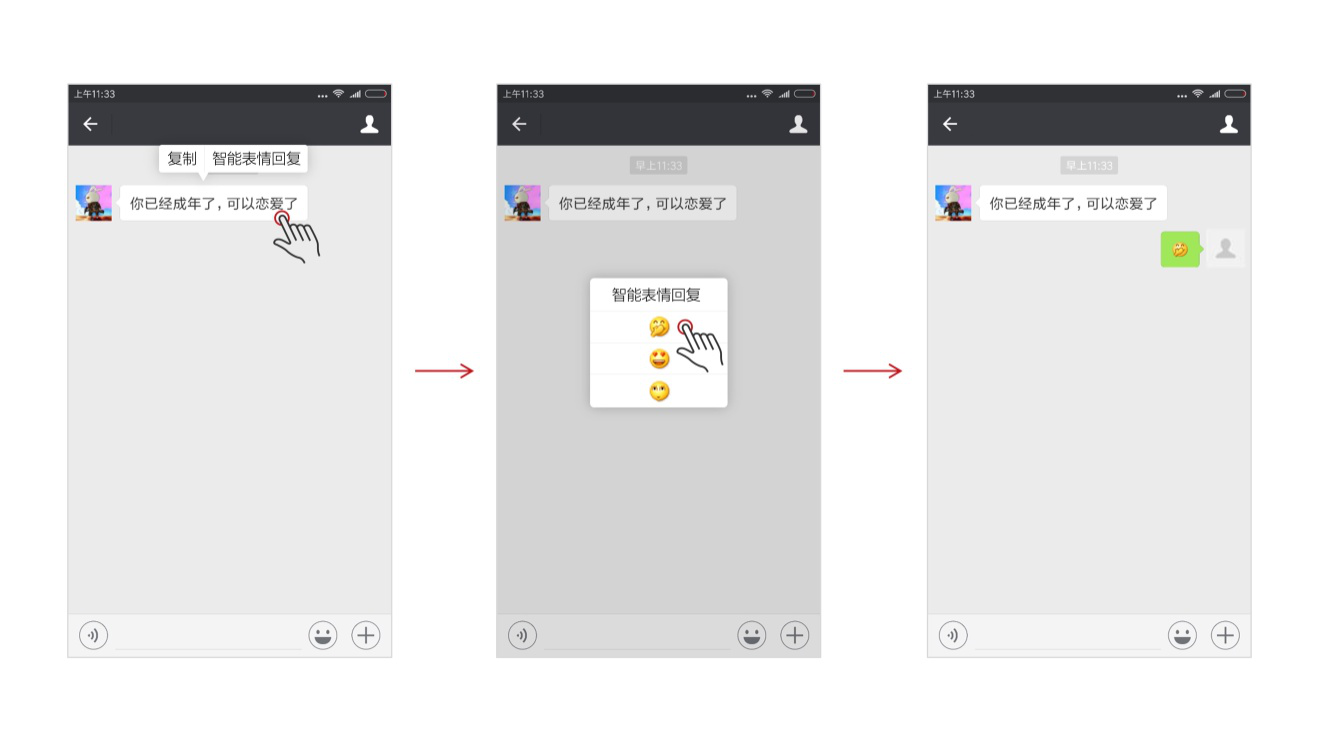
收到消息后,用户只需轻松点击对话文本,选择智能表情回复,就可以点选表情进行回复了,省去了在大量表情库里苦苦寻觅可用表情的麻烦。
目前三角兽能够智能生成回复的表情包括20个,除了常规的开心、难过等简单类别,更能通过计算判断回复尴尬、惊恐、卖萌等复杂表情。
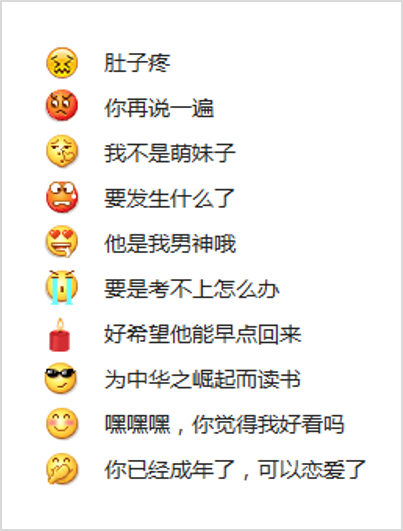
智能表情生成示例
技术原理:
抓取数亿级带有表情标签的公开对话语料,经数据清理后选择出数千万高质量数据,使用这些数据训练CNN模型构建智能情绪分类系统,下图为带有表情标签的原始训练数据示例:

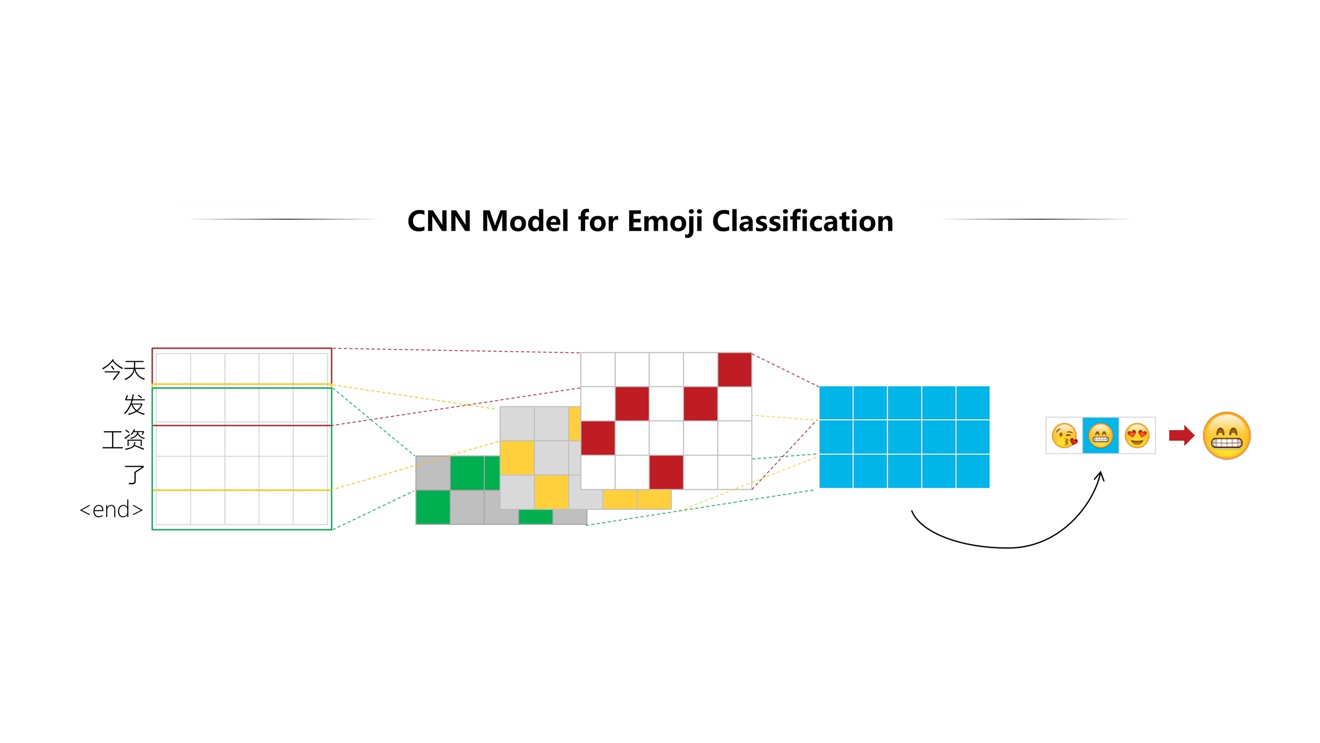
CNN模型判断一段文本的情绪分类分为以下阶段:
Embedding Layer
查询输入句子中每个词的Word Embedding,组合成句子的二维语义表示
Convolution Layer
定义多个大小的卷积窗口,以覆盖多种长度的相邻词组
滑动各窗口对句子的二维语义表示进行卷积操作,获取相邻词组的语义特征
Max-Pooling Layer
通过取最大值方式,分别对每个窗口生成的语义特征进行采样,以减少特征维数并捕获最重要语义特征信息
Full connected layer
将各窗口Pooling之后的语义特征进行拼接,并经过非线性变换输出整句语义特征
Softmax Layer
整句语义特征经过Softmax层计算得到各表情的概率预估值
最终选择出概率最大的N个情绪类别作为最终输出。
简单地说,就是通过多次卷积计算,和特征提取,最终把整个语句映射到多个类别中,取概率最高的类别来进行表情匹配。
3.智能自动回复
智能理解文本内容,自动生成回复建议供用户选择回复。
顾名思义,这个功能赋予了系统智能自动回复的能力。当用户收到某条信息时,系统可以智能理解文本内容,生成几个选项,作为可回复句子的备选,让回复消息也变成了动一下手指就能解决的事情。这在大大为用户提高了回复效率的同时,也能保证回复质量:使对话持续且有效地进行,避免答非所问的“尬聊”,实现对用户问题的有效而精准的回复。
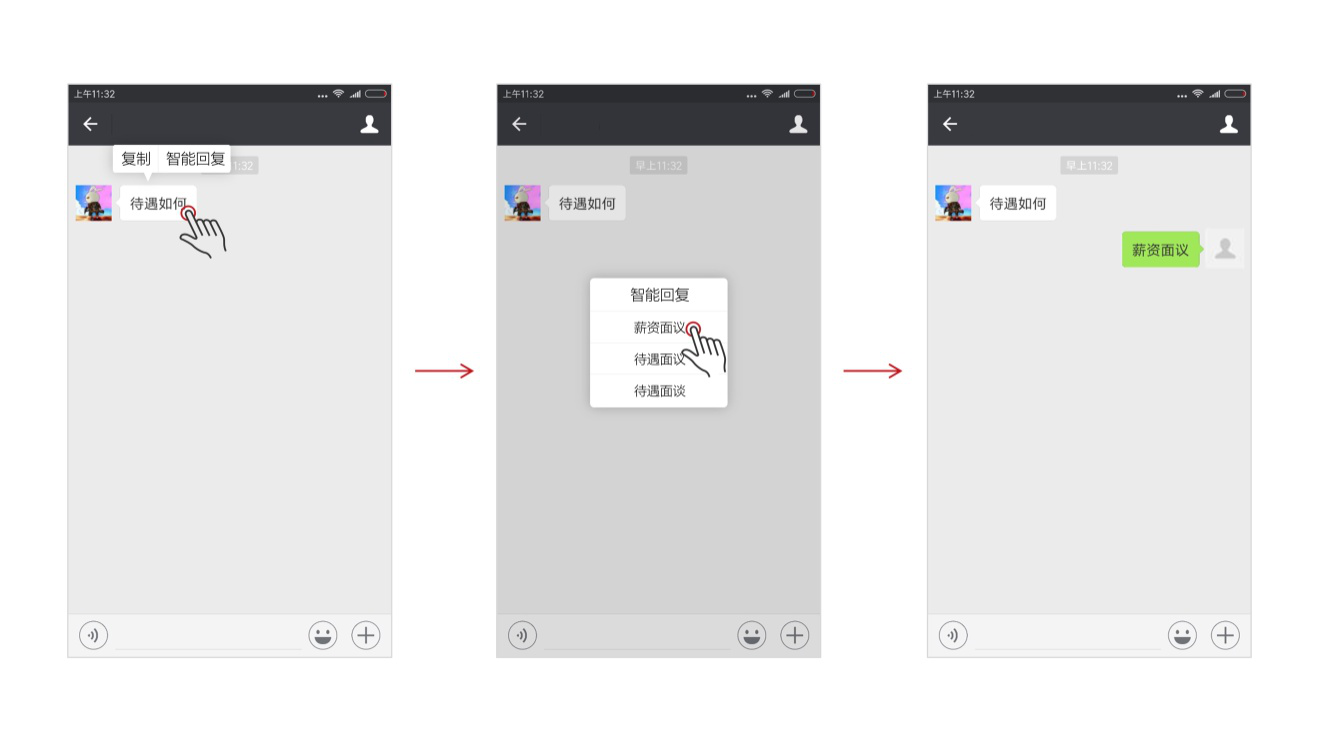
在忙碌的生活中,我们经常会有不方便与其他人进行聊天的情况。而这时,借助智能自动回复的能力,聊天也变成了一键可实现的事情:只需要选中文本,选择智能回复功能,并在备选项中选择自己想回复的内容条目,便可直接进行回复。
技术原理:
从互联网上抓取数亿量级的人与人间的公开对话语料,使用这些海量数据训练Seq2Seq深度学习模型构建智能自动回复系统。
原始对话训练数据示例
Seq2Seq生成式对话模型:
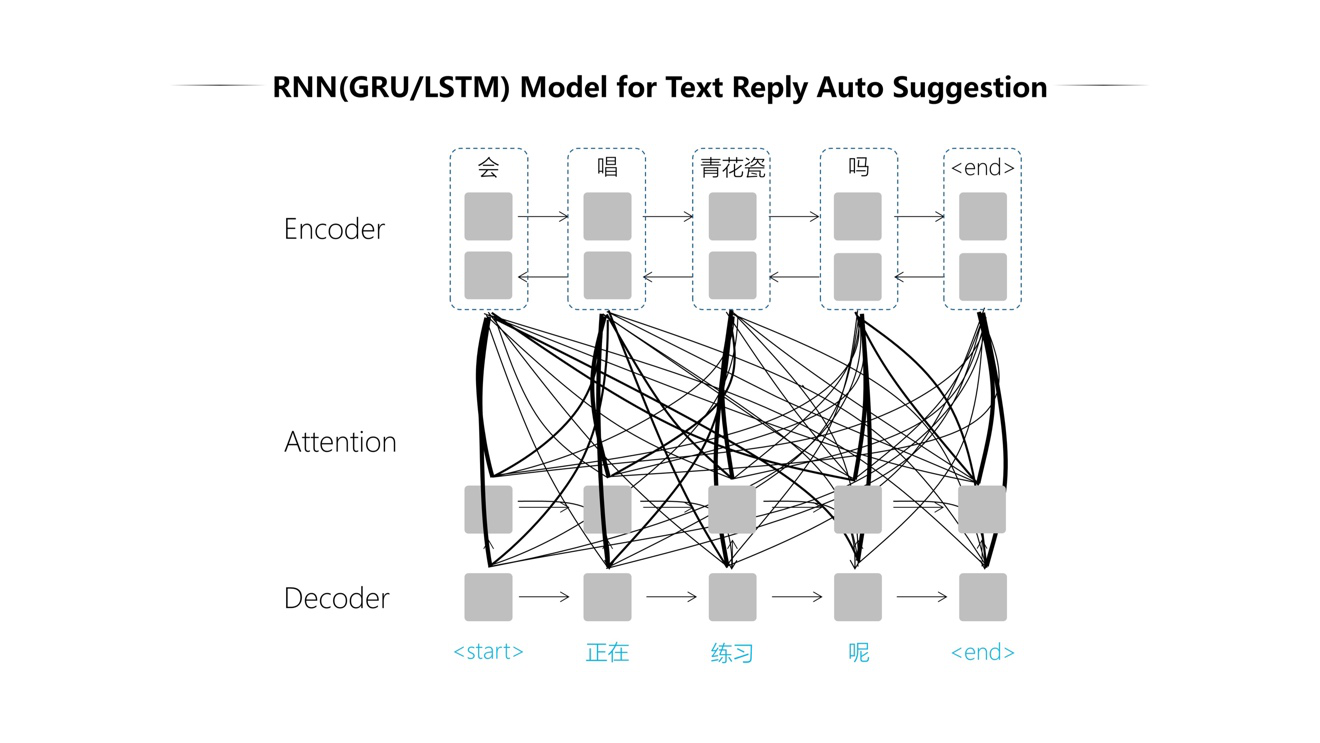
Seq2Seq模型生成自动回复的过程分为Encoder和Decoder先后两个阶段:
在Encoder阶段,按照输入句中词序的正反两个方向逐个处理每个词:
通过GRU/LSTM单元来融合以下因素,生成句首到当前词的左子句语义表示Li
当前词的语义表示Xi
左侧上一位置左子句的语义表示Li-1
通过GRU/LSTM单元来融合以下因素,生成句尾到当前词的右子句语义表示Ri
当前词的语义表示Xi
右侧下一位置右子句的语义表示Ri-1
在Decoder阶段,逐个生成输出句中的每个词
通过GRU/LSTM单元融合以下因素,生成当前位置的隐层语义表示Si:
由Attention Mechanism生成当前位置的语义表示Ci
Ci计算过程如下:
Encoder阶段每个词的左右子句语义表示(Lj和Rj)拼接为Hj
根据Si-1及Hj,计算当前位置与每个Hj的权重aij
Ci 为所有Hj与aij乘积的加和
生成序列中上一位置词的语义表示Yi-1;
生成序列中上一位置的隐层表示Si-1
基于当前位置的隐层语义表示Si,使用Softmax层计算得到词表中每个词的概率分布,并选择出最大概率的词为当前位置输出词
当选择出的输出词为句尾标志时,整句生成结束
在实际Decoder过程中,使用Beam Search方法最终输出概率最大的N个输出序列。
可以将我们生成回复的模型近似地想象为一个“翻译机”。当然,这和传统意义上的翻译并不是一回事,只是为了帮助大家理解这一过程打的比方。这个“翻译机”采用了逐词生成机制,根据输入语句所包含的语义,以及上一阶段生成的文字,对现阶段将要生成的词语进行概率计算,最终逐个词生成并连贯为一句话。
以上三个功能均由三角兽提供算法模型,并运行在麒麟970芯片上,充分展示手机本地端做智能语义处理的能力。一般来说,移动端AI由云端与终端两部分组成,由于云端受限于时延和安全性等,催生AI的“推断”部分向终端下沉。AI芯片级的自然语言处理能力,具有更高算力,更低时延、更低功耗,也相对安全。不难发现,为底层终端注入AI能力可谓优势明显,拥有巨大潜力与商业价值。
这些功能也更能在很大程度上优化用户体验:一方面,这些功能省去了移动端上的繁琐操作,不但能直接提取关键信息进行简便操作,还使消息回复也变得轻松快捷,大大提升了交互的便捷性;另一方面,在高效提升效率的同时,对话过程的生动流畅性也能得到保证,对话精确有效,且高度拟人化。这几大功能的结合,必将重新定义用户对手机交互的心理认知。
三角兽在与企业的合作中也在积极探索,寻找最优解决方案,发扬自身技术能力,为企业和用户不断提升效率、降低成本,打造更佳使用体验。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 三角兽
华为
三角兽
华为