
「第二个太阳系」被AI发现?
NASA和Google联合宣布:谷歌的人工智能和开普勒天文望远镜共同了发现「第二个太阳系」 ,AI在这其中发挥了怎样的作用?
NASA的科学家利用AI系统的强大计算能力对开普勒望远镜获取的海量数据进行自动化筛选,并在已经归档的数据中发现了一个此前在进行人工分析时被忽略的微弱异常信号,最终证明这是恒星开普勒-90周围存在的第八颗行星。

简单的说,Google的AI技术提高了对开普勒数据的分析效率。通俗的讲,google的AI让处理数据的能力更加智能化和高效了,就好比以前的计算机提高了人脑的计算效率一样。
那么,这项技术的神秘面纱是什么?开普勒望远镜所收集的数据又是什么呢?这项技术为何能高效处理这些数据来发现“第二个太阳系”的呢?
首先我们来回答第一个问题——谷歌的这项AI技术是什么?
神经网络技术。神经网络的构筑理念是受到生物(人或其他动物)神经网络功能的运作启发而产生的人工智能技术。神经网络已经被用于解决各种各样的问题,这些问题都是很难被传统基于规则的编程所解决的,例如机器视觉和语音识别。神经元在通过简单计算后将相关信息传递给下一级的神经元进行继续处理,以此类推。通过这种方式,计算机可以学会识别猫猫狗狗。当然,通过学习开普勒太空望远镜的光线信号,也可以用来识别地外行星。
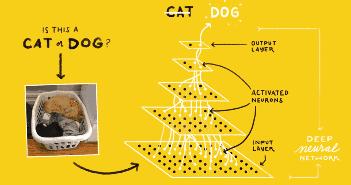
第二个问题——开普勒望远镜所收集的数据是什么?
先来了解地外行星侦测法——凌日法。如果一颗行星从母恒星盘面的前方横越时,将可以观察到恒星的视觉亮度会略微下降一些,这颗恒星变暗的程度取决于行星相对于恒星的大小。开普勒太空望远镜使用的就是凌日法,望远镜在长时间里对超过十万颗恒星进行监视,扫描并记录每一颗恒星在不同位置的亮度变化。这种呈U形的明暗信号变化模式通过白色的线条来表示。下图中蓝色的点状分布,正是 NASA 在分析这些光变曲线后,得出“开普勒天体”的数据。
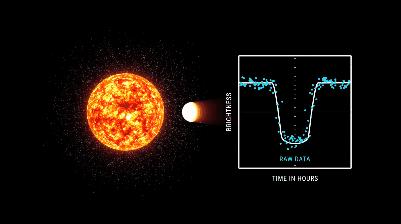
第三个问题——这项技术为何能高效处理这些数据以此来发现“第二个太阳系”?
简单来说,是科学家让电脑学会了辨认行星的特征。
过往,天文学家寻找系外行星的主要途径是通过自动化软件(使用的是特定编程,不具备AI的智能学习系统)或人工来对大量产生于开普勒望远镜的数据进行分析。过去四年,开普勒望远镜每 30 分钟拍摄一张照片,创造了约 140 亿个数据点。这 140 亿个数据点可以转化为大约 2 万亿个可能的行星轨道!对于计算能力最强大的计算机来说,这样的分析也是一个浩大的工程,而且会非常耗时。为了让这样的分析过程更快更有效,研究人员们转向了机器学习。
研究人员通过训练神经网络,让计算机学会了识别行星从恒星前方横越时产生的微弱信号(注意:先前的技术是不能让“计算机自己”识别这些信号的,需配合人的操作才行,这样先前的工作效率就低了很多)。
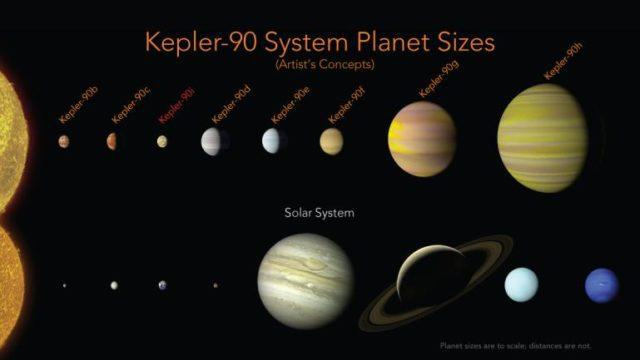
在使用这种技术对已知的 670 个多行星系统的扫描过程中,发现了行星开普勒 90i——恒星开普勒-90周围发现的第8颗行星(位于第六轨道)。至此,人类在太阳系外发现第一个由8个行星构成的行星系,也就是第二个太阳系。(下图上面一排是“第二个太阳系”,下面一排是我们的太阳系)。
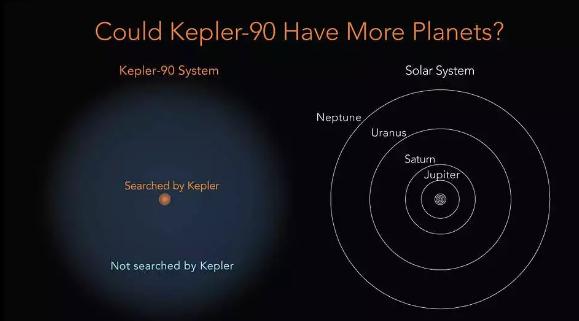
实际上:Google已经开始将这套AI用在开普勒观测到的15万颗恒星数据上。下图中橙色区域为此次已经探索的区域,而广阔的未被探索区域(蓝色)中有可能还有大量的行星未被发现,预计不久之后又会有新的消息曝出,说不定会发现类似地球的行星,更多的“太阳系”。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 AI
太阳系
AI
太阳系